Spark Introduce and Install
介绍 Spark 的历史,介绍 Spark 的安装与部署,介绍 Spark 的代码架构 等
Spark 发源于 美国加州大学伯克利分校 AMPLap 大数据分析平台
Spark 立足于内存计算、从多迭代批量处理出发
Spark 兼顾数据仓库、流处理、图计算 等多种计算范式,大数据系统领域全栈计算平台
University of California, Berkeley
1. Spark 的历史与发展
- 2009 年 : Spark 诞生于 AMPLab
- 2014-02 : Apache 顶级项目
- 2014-05 : Spark 1.0.0 发布
2. Spark 之于 Hadoop
Spark 是 MapReduce 的替代方案, 且兼容 HDFS、Hive 等分布式存储层。
Spark 相比 Hadoop MapReduce 的优势如下 :
- 中间结果输出
- 数据格式和内存布局
- 执行策略
- 任务调度的开销
Spark用事件驱动类库AKKA来启动任务, 通过线程池复用线程避免进线程启动切换开销
3. Spark 能带来什么 ?
- 打造全栈多计算范式的高效数据流水线
- 轻量级快速处理, 并支持 Scala、Python、Java
- 与 HDFS 等 存储层 兼容
4. Spark 安装与部署
Spark 主要使用 HDFS 充当持久化层,所以完整的安装 Spark 需要先安装 Hadoop.
Spark 是计算框架, 它主要使用 HDFS 充当持久化层。
Linux 集群安装 Spark
- 安装 JDK
- 安装 Scala
- 配置 SSH 免密码登陆 (可选)
- 安装 Hadoop
- 安装 Spark
- 启动 Spark 集群
1 | MS=/usr/local/xsoft |
4.1 安装 Spark
1 | (1). tar -xzvf spark-3.0.0-bin-hadoop2.7.tgz |
4.2 启动 Spark 集群
在 Spark 根目录启动 Spark
1 | ./sbin/start-all.sh |
启动后 jps 查看 会有 Master 进程存在
1 | ➜ spark-1.5.2-bin-hadoop2.6 jps |
4.3 Spark 集群初试
可以通过两种方式运行 Spark 样例 :
- 以 ./run-example 的方式执行
1 | ➜ cd /usr/local/xSoft/spark |
- 以 ./Spark Shell 方式执行
1 | scala> import org.apache.spark._ |
-
通过 Web UI 查看集群状态
http://masterIp:8080
<img src="/images/spark/spark-introduce-05.png" width=“740” height=“400”/img>
4.4 Spark quick start
quick-start : https://spark.apache.org/docs/latest/quick-start.html
./bin/spark-shell
1 | scala> val textFile = sc.textFile("README.md") |
5. Spark 生态 BDAS
- Spark 框架、架构、计算模型、数据管理策略
- Spark BDAS 项目及其子项目进行了简要介绍
- Spark 生态系统包含的多个子项目 : SparkSql、Spark Streaming、GraphX、MLlib
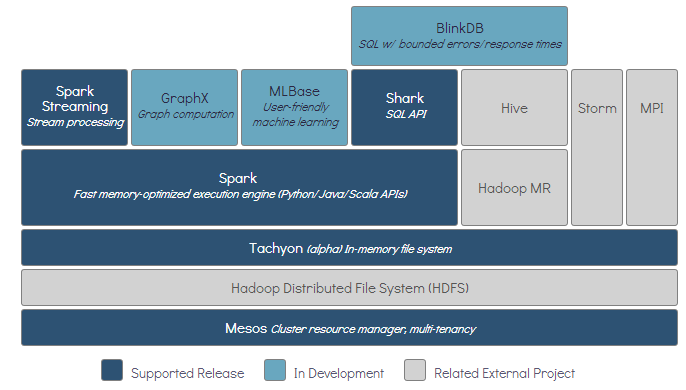
- Spark 是 BDAS 核心, 是一 大数据分布式编程框架
6. Spark 架构
- Spark 的代码结构
- Spark 的架构
- Spark 运行逻辑
6.1 Spark 的代码结构
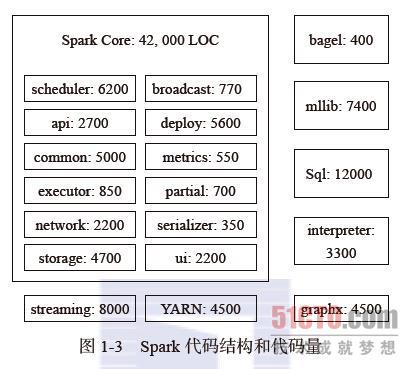
1 | scheduler:文件夹中含有负责整体的Spark应用、任务调度的代码。 |
6.2 Spark 的架构
Spark架构采用了分布式计算中的Master-Slave模型。
| Role | description |
|---|---|
| Master | 对应集群中的含有Master进程的节点, 集群的控制器 |
| Slave | 集群中含有Worker进程的节点 |
| Client | 作为用户的客户端负责提交应用 |
| Driver | 运行Application的main()函数并创建SparkContext。负责作业的调度,即Task任务的分发 |
| Worker | 管理计算节点和创建Executor,启动Executor 或 Driver. 接收主节点命令与进行状态汇报 |
| Executor | Worker node执行任务的组件,负责 Task 的执行,用于启动线程池运行任务 |
| ClusterManager | Standalone 模式中为 Master, 控制整个集群, 监控Worker |
| SparkContext | 整个应用的上下文, 控制App的生命周期 |
| RDD | Spark的基本计算单元,一组RDD可形成执行的 DAG |
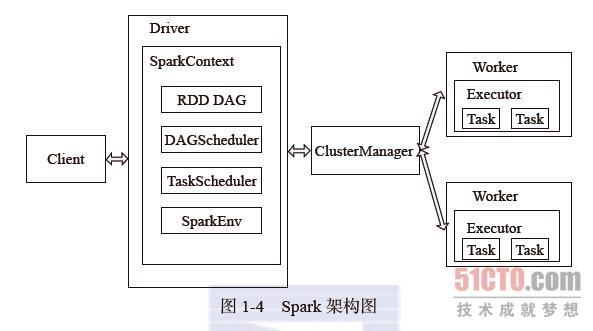
| Num | Spark App 流程 |
|---|---|
| 1. | Client 提交应用 |
| 2. | Master 找到一个 Worker 启动 Driver |
| 3. | Driver 向 Master 或者 资源管理器申请资源,之后将应用转化为 RDD Graph |
| 4. | DAGScheduler 将 RDD Graph 转化为 Stage的有向无环图 提交给 TaskScheduler |
| 5. | TaskScheduler 提交 task 给Executor执行 |
| 6. | 在任务执行的过程中,其他组件协同工作,确保整个应用顺利执行 |
在执行阶段,Driver 会将 Task 和 Task所依赖的file 和 jar 序列化后传递给对应的 Worker机器,同时 Executor对相应数据分区的任务进行处理。
7. 小结
由于 Spark 主要使用 HDFS 充当持久化层,所以完整的使用 Spark 需要预先安装 Hadoop.
Spark 将分布式的内存数据抽象为弹性分布式数据集 (RDD), 并在其上实现了丰富的算子,从而对 RDD 进行计算,最后将 算子序列 转化为 DAG 进行执行和调度。
Spark的Python API几乎覆盖了所有Scala API所能提供的功能. 但的确有些特性,比如Spark Streaming和个别的API方法,暂不支持。
具体参见《Spark编程指南》的Python部分
体会了 函数式 编程. 个人认为 scala、python 比较适合写 spark 程序.
Checking if Disqus is accessible...