Improving DNN (week3) - Hyperparameter、Batch Regularization
Hyperparameter Tuning process、Normalizing Activations in a network
Fitting Batch Norm into a neural network、Why does Batch Norm work?、Batch Norm at test time
Softmax regression、TensorFlow
1. Hyperparameter Tuning process
正常情况有如下超参数:
| Hyperparameter | Desc | Importance level |
|---|---|---|
| α | 最重要 | 1 |
| hidden units | 2 | |
| mini-batch size | 2 | |
| β | 2 | |
| layers | 3 | |
| learning rate decay | 3 | |
| 最不重要 | 4 |
颜色表示重要性,以及调试过程中可能会需要修改的程度.
那么如何选择超参数的值呢?:
- 首先是粗略地随机地寻找最优参数
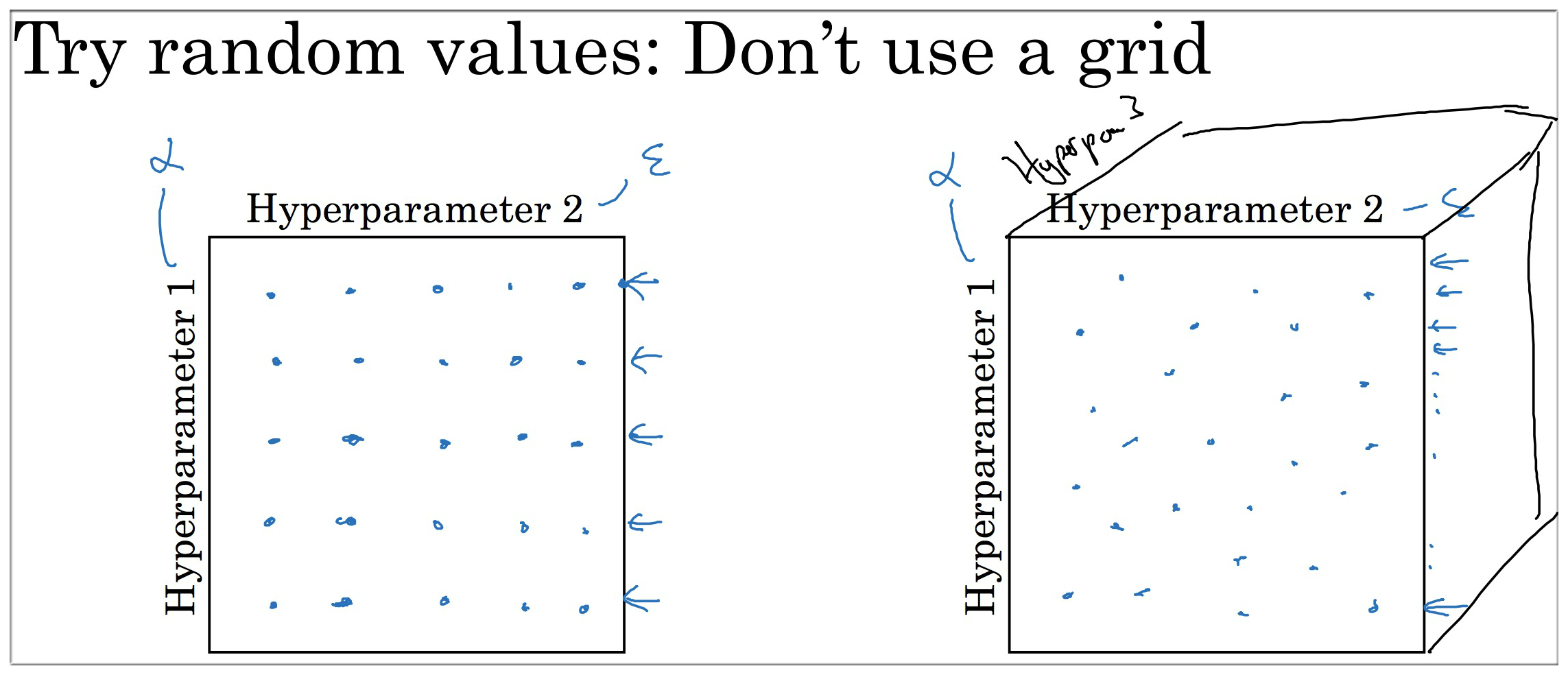
建议使用图右的方式,原因如下:
对于图左的超参数分布而言,可能会使得参考性降低,我们假设超参1是学习率α,超参2是ε,根据week2中Adam算法的介绍,我们知道ε的作用几乎可以忽略,所以对于图左25中参数分布来说,其本质只有5种参数分布。而右边则是25种随机分布,更能帮助我们选择合适的超参数.
其次在上面找到的最优参数分布周围再随机地寻找最有参数
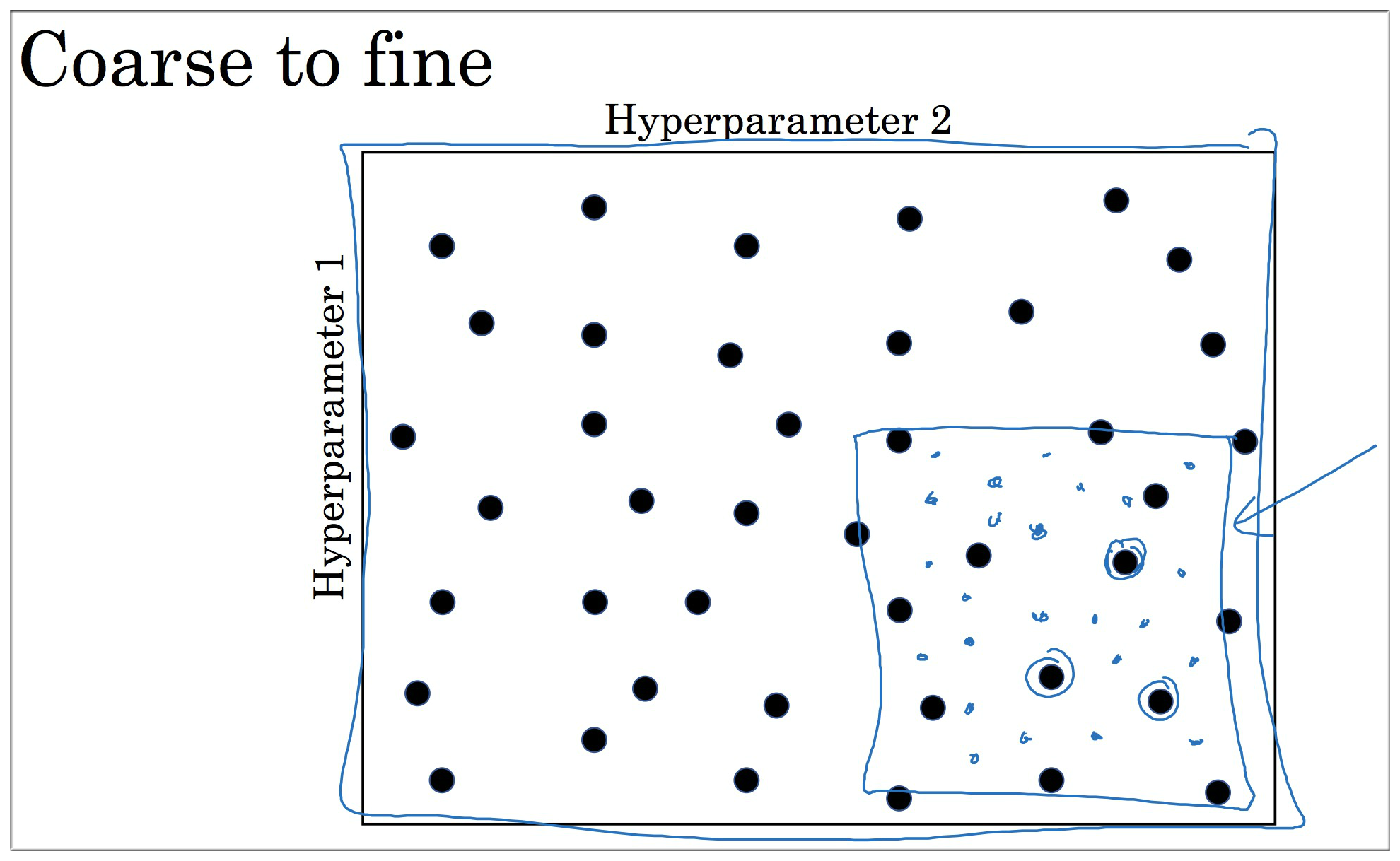
2. Using an appropriate scale to pick hyperparameters
上一节提到的的随机采样虽然能帮助我们寻找最优参数分布,但是这有点像大海捞针,如果能够指出参数取值的范围,然后再去寻找最优的参数分布岂不是更加的美滋滋?那如何为超参数选择合适的范围呢?
此时注意: 如按照线性划分的话(如下图),那么随机采样的值 90% 的数据来自 [0.1,1] 这个区间, 这显然与不太符合随机性.

所以为了改进这一问题,我们需要将区间对数化来采样.
举个🌰: 我们将 [0.0001,1] 转化成四个区间 [0.0001,0.001], [0.001,0.01], [0.01,0.1], [0.1,1], 再转化成对数就是 [-4,-3], [-3,-2], [-2,-1], [-1,0].
(,其他同理取指数).
然后我们可以用 Python 中提供的方法来实现随机采样:
1 | r = -4*np.random.rand() # rand()表示在[0,1]上均匀采样, 最后的采样区间是[-4, 0] |

同理这里也不能使用线性轴来采样数据,我们可以通过对 1-β=0.1,……,0.001 来间接采样。转化成 [0.1, 0.01], [0.01,0.001], 转化成对数指数 [-1,-2],[-2,-3]。
即:
当 β 接近 1 时, β 就会对细微的变化变得很敏感.
for example : 0.999, 0.9995 => 1000 -> 2000
所以你需要更加密集的取值,在 β 接近 1 的时候.
3. Hyperparameters tuning in practice: Pandas vs Caviar
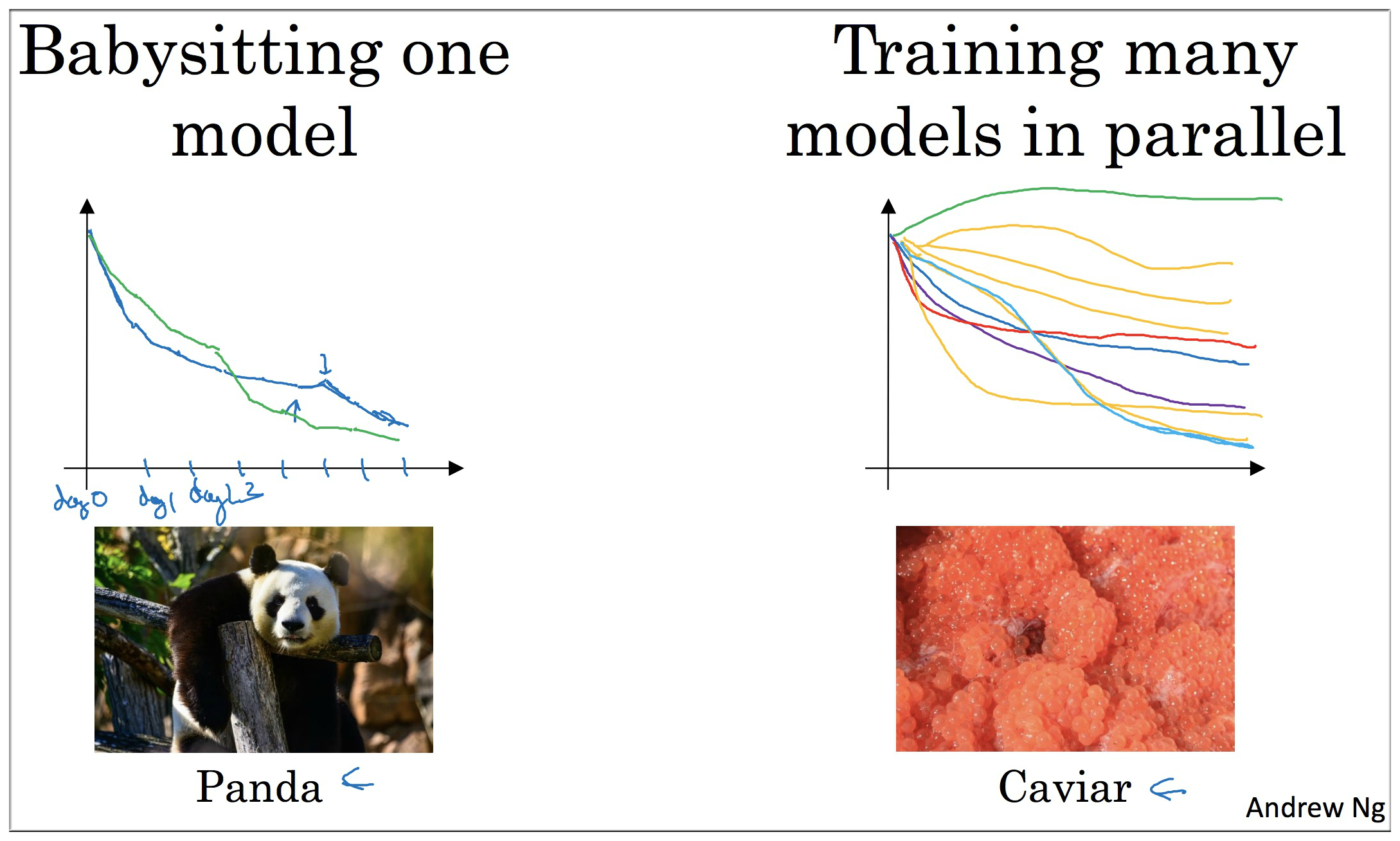
Babysitting one model:
这种方法适用于有足够的数据集,但是 GPU,CPU 资源有限的情况,所以可能只能训练一个模型,然后每天对模型做某一项超参数的修改,查看效果是否变得更好.
例如第一天令所有超参数随机初始化。到了第二天发现效果还不错,此时可以去增加学习率(也可以修改其他参数)。……,到了某一天加入修改了mini-batch size,结果效果明显减弱,这时则需要重新恢复到前一天的状态。
总的来说这一过程就像熊猫一样,只照顾一个宝宝,多的照顾不过来.
Train many models in parallel:
这种方法适用于财大气粗的情况,即并行训练多个模型,最后选出效果最好的一个即可。这就像鱼子酱一样,一下生多大一亿的孩子.
4. Normalizing Activations in a network
不仅要归一化输入数据 ,隐藏层的数据也是要归一化的. 一般来说隐藏层数据有 和 两种,Andrew Ng 推荐归一化 .
Batch 归一化 由 Sergey loffe 和 Christian Szegedy 两位研究者创造.
Batch 归一化,会使你的参数搜索变得容易, 使神经网络对超参数的搜索更加稳定. 这样也会使得你容易训练深层神经网络。
输入数据 归一化方法:
m 为 mini-batch 中的 m, 而不是整个训练集
隐藏层数据归一化方法:
上面的归一化后的数据 都是服从均值为 0,方差为 1 的,显然这样不能满足咱们的需求,所以还需要做进一步处理,如下:
上式中的 可以设置方差, 可以设置均值.
你也许不想隐层单元值必须是平均值0 和 方差1, 比如你有一个 sigmoid 函数,你不想让它的值完全集中在这里, 你不想使他们平均值和方差一直是0和1, 这样可以更好的利用非线性的 Sigmoid 函数, 而不是所有值都集中在线性的区域, 和 可以确保所有的 值,可以是你想赋予的任意值. 或者 它的作用是保证隐藏的单元已使均值和方差标准化. 那里均值和方差由两参数控制. 和 学习算法可以设置为任何值. 所以它的真正作用是使均值和方差标准化. 有固定的均值和方差,均值和方差可以是0和1,也可以是其他值,由 和 确定.
In practice, normlizing Z^{\[2\]} is done much more often.
5. Fitting Batch Norm into a neural network
adding batch Norm to a network
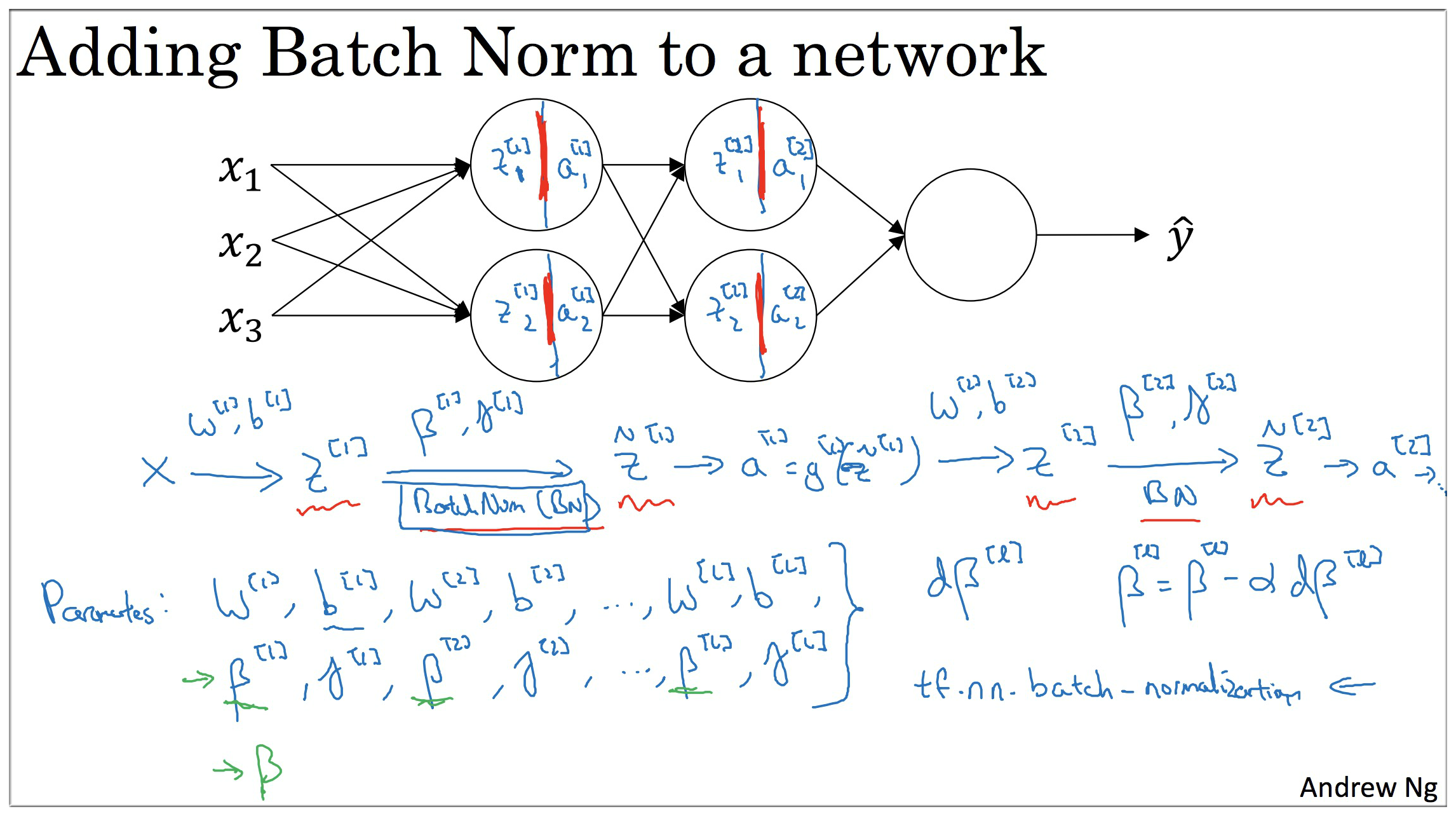
working with mini-batches
一般的方法中
在上面归一化数据过程中需要减去均值,所以 这一项可以省略掉,所以归一化后是
为了能够使数据分布更加满足我们的要求,可以用如下公式
Implementing gradient descent
for t= 1,……,numMinBatches
- 计算基于第 批数据的前向传播
- 在计算反向传播时使用 , 得到
- 更新参数
6. Why does Batch Norm work?
原因一:
batch norm 可以使得权重比你的网络更滞后或更深层,为了更好地理解可以看下面的例子:
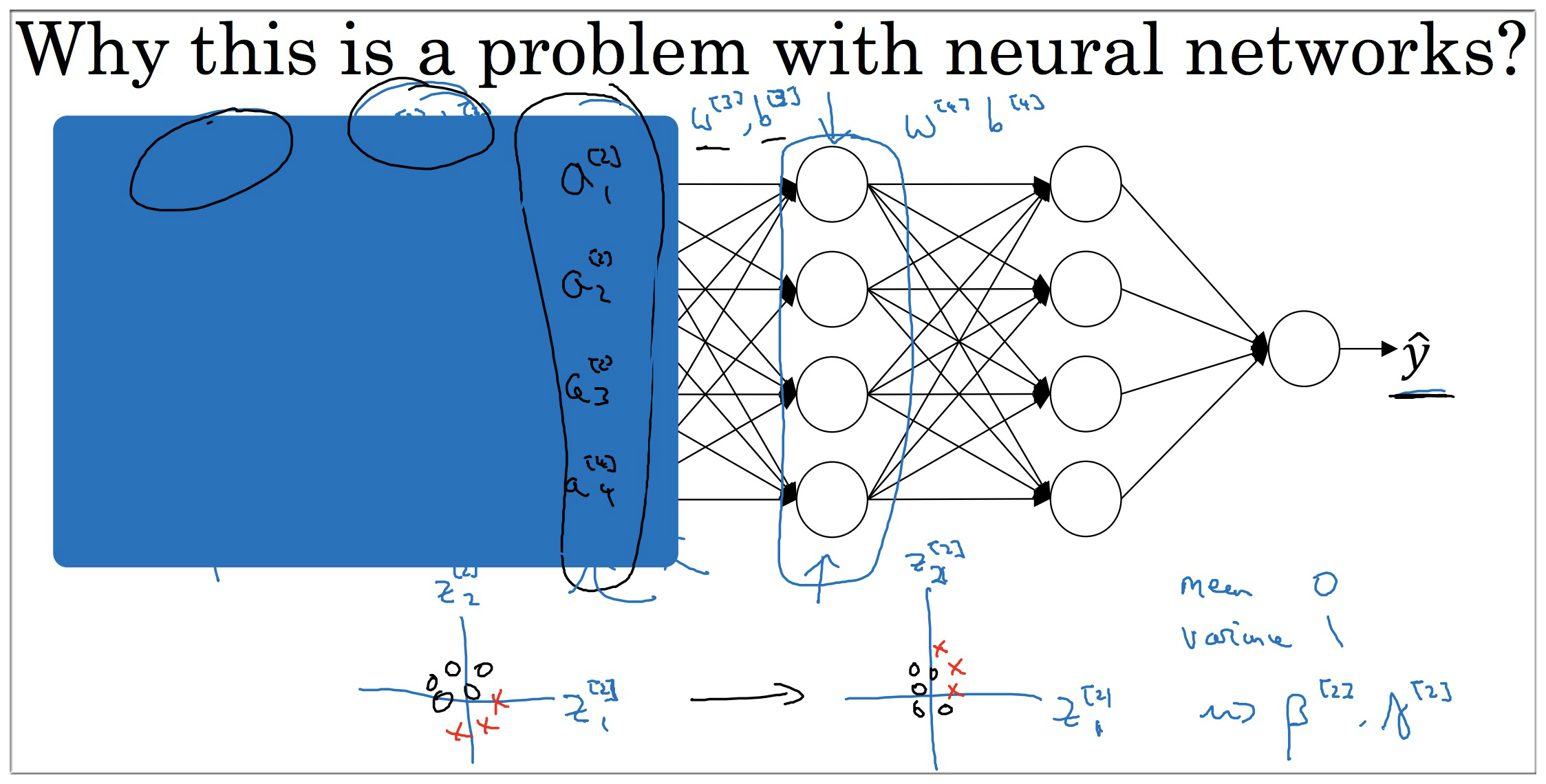
如上图所示,假设我们现在要计算第三层隐藏层的值,很显然该层的计算结果依赖第二层的数据,但是第二层的数据如果未归一化之前是不可知的,分布是随机的。而如果进行归一化后,即 \tilde{z}^{\[2\]}=γ^{\[2\]}z\_{norm}^{\[2\]}+β^{\[2\]} 可以将第二层数据限制为均值为 β^{\[2\]}, 方差为 γ^{\[2\]} 的分布,注意这两个参数并不需要人为设置,它会自动学习的。所以即使输入数据千变万化,但是经过归一化后分布都是可以满足我们的需求的,更简单地说就是归一化数据可以减弱前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习。
原因二:
batch norm 奏效的另一个原因则是它具有正则化的效果。其与dropout有异曲同工之妙,我们知道dropout会随机的丢掉一些节点,即数据,这样使得模型训练不会过分依赖某一个节点或某一层数据。batch norm也是如此,通过归一化使得各层之间的依赖性降低,并且会给每层都加入一些噪声,从而达到正则化的目的
Batch 它限制了在前层的参数更新,会影响数值分布的程度,第三层看到的这种情况,因此得学习. batch 归一化减少了输入值改变的问题, 它的确是这些值变得更稳定. 神经网络的之后层就会有更坚实的基础. 即使输入分布改变了一些,它会改变得更少,它做的是 当前层保持学习,当层改变时,迫使后层, 适应的程度减少了,你可以这样想,它减弱了前层参数的作用,与后层参数的作用之间的联系,它使得网络每层都可以自己学习. 稍稍独立于其它层,这有助于加速整个网络的学习.
batch norm 中有一个作用,可以起到轻微 正则化 的作用. (因为添加的噪音很微小,所以并不是巨大的正则化), 你可以将 batch norm 和 dropout 一起使用.
dropout, 你应用较大的 mini-batch 比如 512,那么可以减少噪音也, 因此减少了正则化的效果. 这是 dropout 的一个奇怪的性质.
batch norm 是一个正则化的规则,而不要把它当做目的. 但是有时候,它会对你的算法有额外的期望和非期望效果.
batch norm 一次只能处理 一个 mini-batch 的数据. 它在 mini-batch 上计算期望与方差.
7. Batch Norm at test time
前面提到的 batch norm 都是基于训练集的,但是在测试集上,有时候可能我们的测试数据很少,例如只有1个,在这个时候进行归一化则显得没多大意义了。那么该怎么办呢?均值 和 方差该如何确定呢?
方法还是有的,而且已经在上面提到过了, 就是第三节所介绍的指数加权平均啦,原理是类似的
假设一共有如下 的批量数据,每组mini-batch 都得到了对应的均值, (方差同理,不详细说明了),即 , 如果测试集数据很少,那么就可以使用指数加权平均的方法来得到测试集的均值和方差。
之后就根据指数加权平均计算得到的值来计算归一化后的输入值即可.

Andrew Ng 语录:
如果将你的神经网络用于测试,你需要单独估算 和 , 在典型的 Batch 归一化运用中,你需要用一个指数加权平均来估算,整个平均数覆盖了所有的 mini-batch .
上个式子 中的,, 是类似加权平均出来的值.
注意:测试集的均值和方差生成的方式不一定非得是上面提到的指数加权平均,也可以是简单粗暴的计算所有训练集的均值和方差,视频中 Andrew Ng 说这也是可行的.
8. Softmax regression
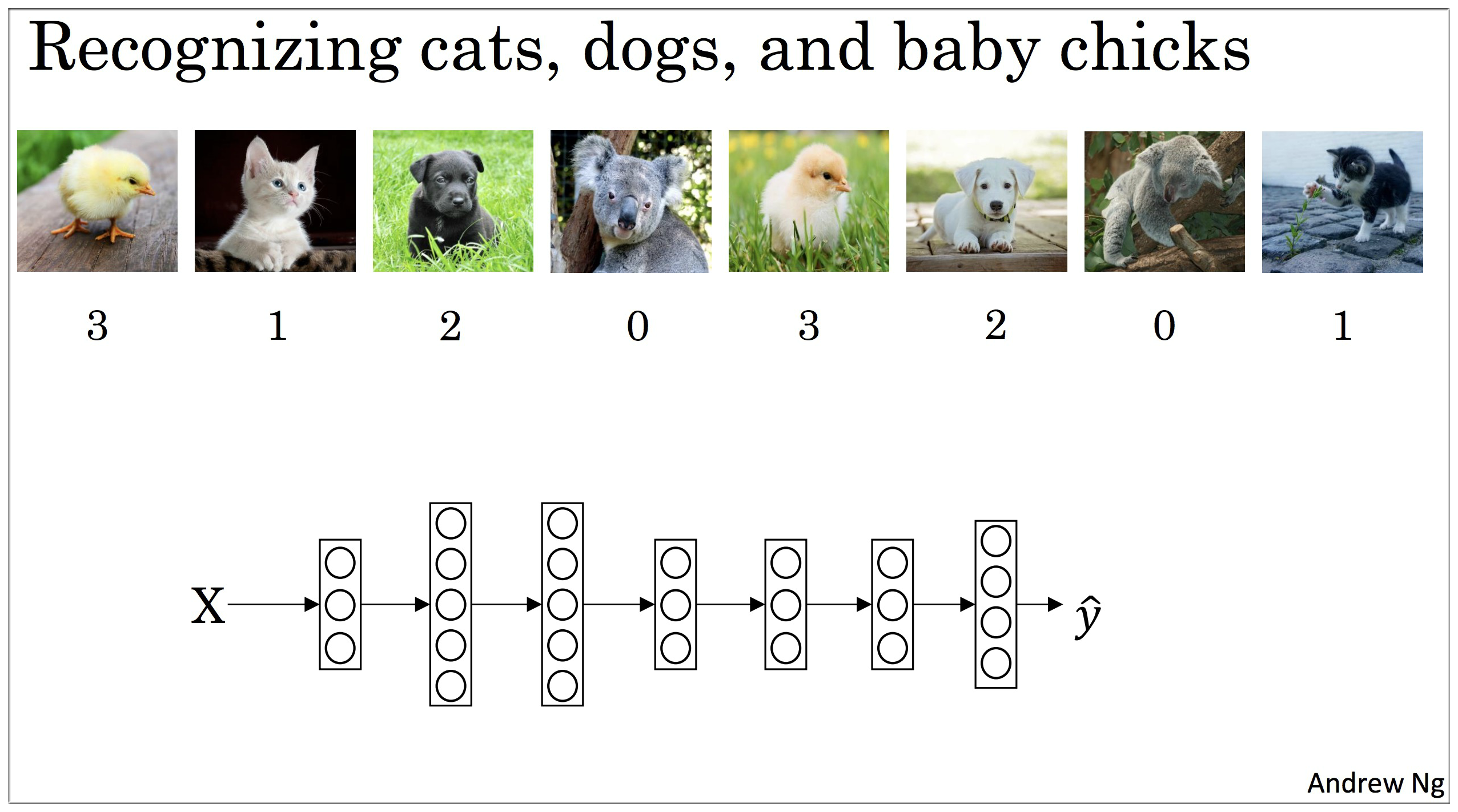
假设第 层有 z^{\[l\]}=w^{\[l\]}a^{\[l-1\]}+b^{\[l\]}, 激活函数为 a^{\[l\]}=\frac{e^{z^{\[l\]}}}{\sum\_{j=1}^{n\_l}e^{z^{\[l\]}\_j}}
该节视频中 Andrew Ng 并没有很详细的介绍 softmax 的原理和公式推导,感兴趣的可以戳如下链接进行进一步了解:
9. Trying a softmax classifier
转载: 具体实践项目可参见softmax分类算法原理(用python实现)
上面的转载实现 softmax 需要再仔细研究.
10. Deep learning frameworks
11. TensorFlow Example
Andrew Ng 演示了 TensorFlow 使用方法.
我推荐一个比较好的 TensorFlow 的练手项目:TensorFlow Example
12. Reference
- 网易云课堂 - deeplearning
- deeplearning.ai 专项课程二第一周
- Coursera - Deep Learning Specialization
- DeepLearning.ai学习笔记汇总
- TensorFlow-Examples
- 吴恩达老师的深度学习课程笔记及资源
Checking if Disqus is accessible...