Convolutional Neural Networks (week2) - deep CNN
理解如何搭建一个神经网络,包括最新的变体,例如残余网络。
1. Why look at case studies?
通过他人的实例可以更好的理解如何构建卷积神经网络,本周课程主要会介绍如下网络
- LeNet-5
- AlexNet
- VGG
- ResNet (有152层)
- Inception
2. Classic networks
2.1 LeNet-5
该网络 1980s 提出,主要针对灰度图像训练的,用于识别手写数字。
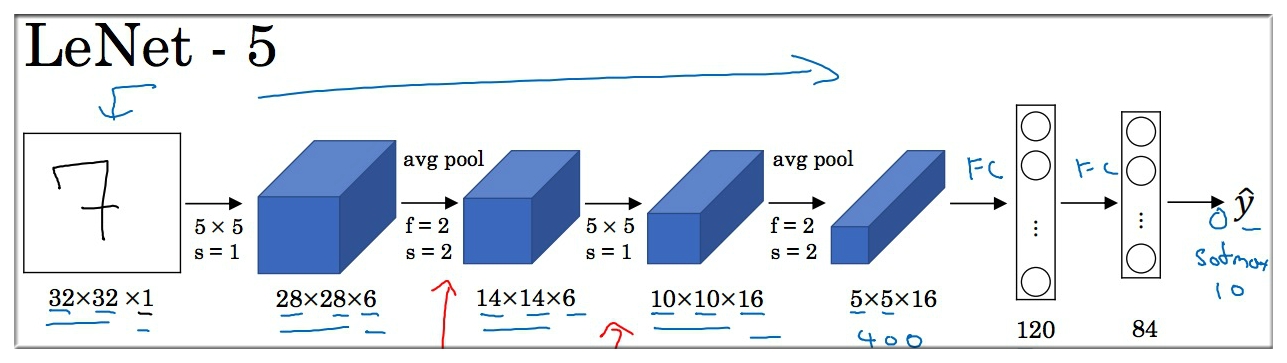
- 当时很少用到 Padding,所以看到随着网络层次增加,图像的高度和宽度都是逐渐减小的,深度则不断增加.
- 当时人们会更倾向于使用 Average Pooling,但是现在则更推荐使用 Max Pooling.
- 最后的预测没有使用 softmax,而是使用了一般的方法.
论文中你会发现,过去人们使用 Sigmoid函数 和 Tanh函数,而不是 ReLu, 这种网路结构的特别之处还在于各网络层之间是有关联的.
2.2 AlexNet
AlexNet 其实和 LetNet-5 有很多相似的地方,如大致的网络结构。不同的地方主要有如下:
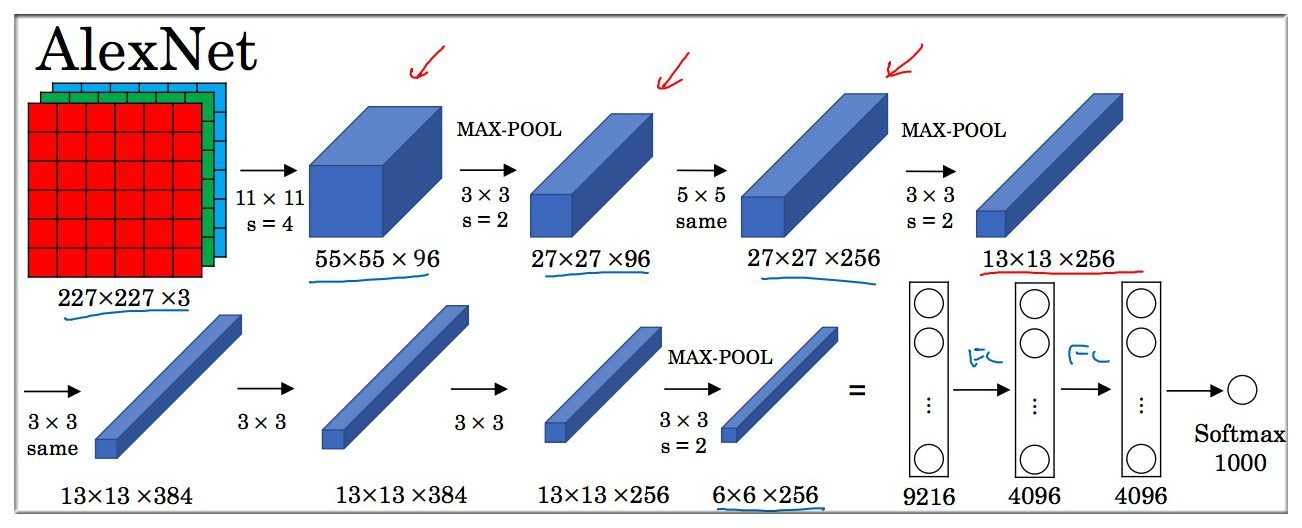
- 激活函数使用的是 Relu,最后一层使用的是 Softmax
- 参数更多,有6000万个参数,而 LeNet-5 只有6万个左右
- 使用 Max Pooling
Local Response Normalization 局部响应归一化 - LRN层,不重要划掉.
这篇论文之后,深度学习逐渐在 CV 方面的关注,与日俱增.
AlexNet 比较复杂,包含大量超参数.
2.3 VGG-16
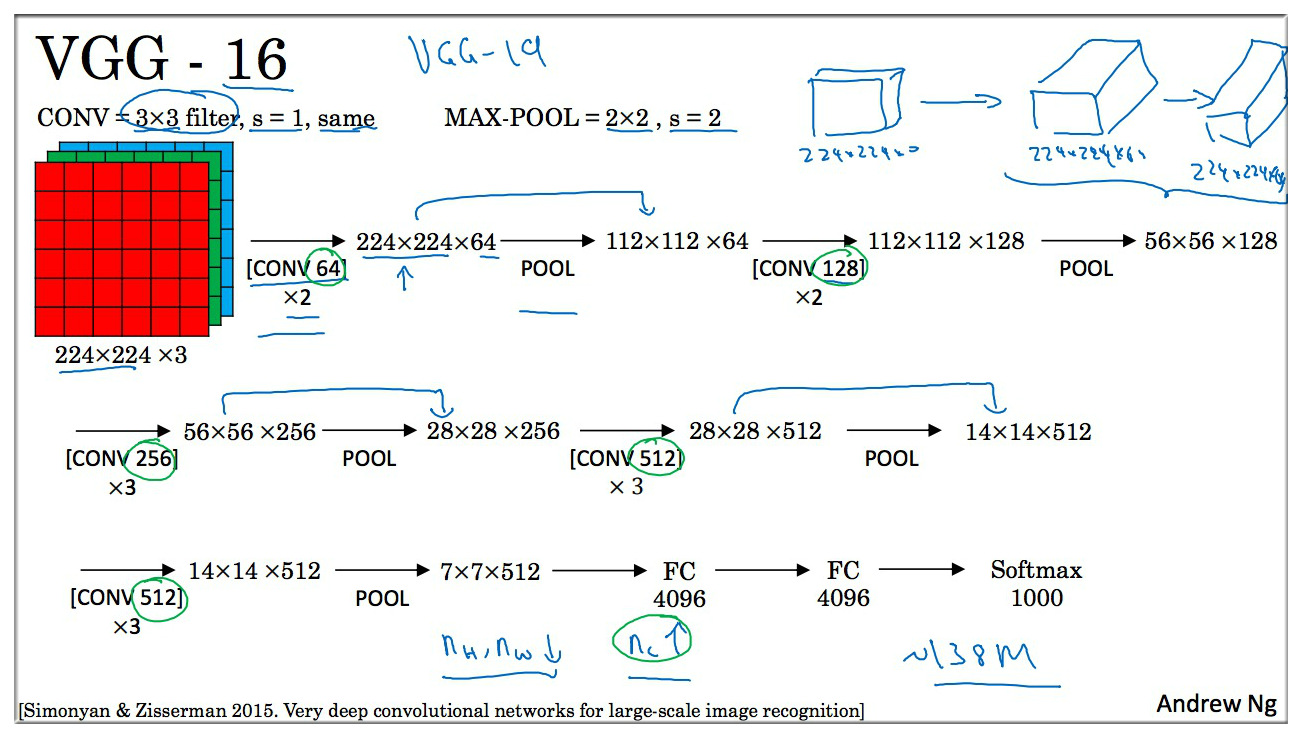
这个网络太牛了,因为它有将近 1.38亿个参数,即使放到现在也是一个很大的网络,但是这个网络的结构并不复杂。下面主要介绍一下上图网络。
首先该网络使用的是 Same卷积,即保证高度和宽度不变,另外因为总共有16层卷积操作,所以就不把每一层都用图像的方式表现出来了,例如 [CONV 64 X2] 表示的是用 64个 过滤器进行 Same卷积 操作2次,即右上角所画的示意图,(224,224,3) -> (224,224,64) -> (224,224,64)
Andrew Ng : 我最喜欢它的一点是,随着网络的加深,图像的 Height 和 Width 都在以一定的规律不断缩小,每次池化之后刚好缩小一半,而信道数量在不断增加. 而刚好也是在每组卷积操作后增加一倍. 也就是说 : 图像缩小的比例和信道增加的比例是有规律的.
上面三个是比较经典的网络,可阅读其论文,Ng吴大师 建议的阅读顺序是 AlexNet->VGG->LeNet。
3. Residual Network (ResNets)
ResNets 发明者是 何恺明、张翔宇、任少卿、孙剑
吴大师表示 “非常深的网络是很难训练的,因为存在梯度消失和梯度爆炸的问题”,为了解决这个问题,引入了 Skip Connection (跳远链接),残差网络正是使用了这个方法。
3.1 残差块 (Residual Block)
首先介绍组成残差网络的单元:残差块(Residual Block),如下图示:
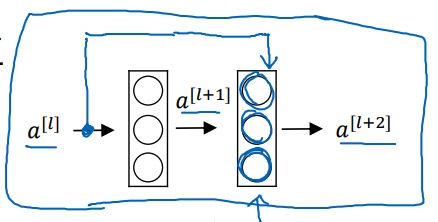
残差块是由两层网络节点组成的, 经过线性变化,再通过Relu激活函数后得到 , 也同理,具体过程如下图示:
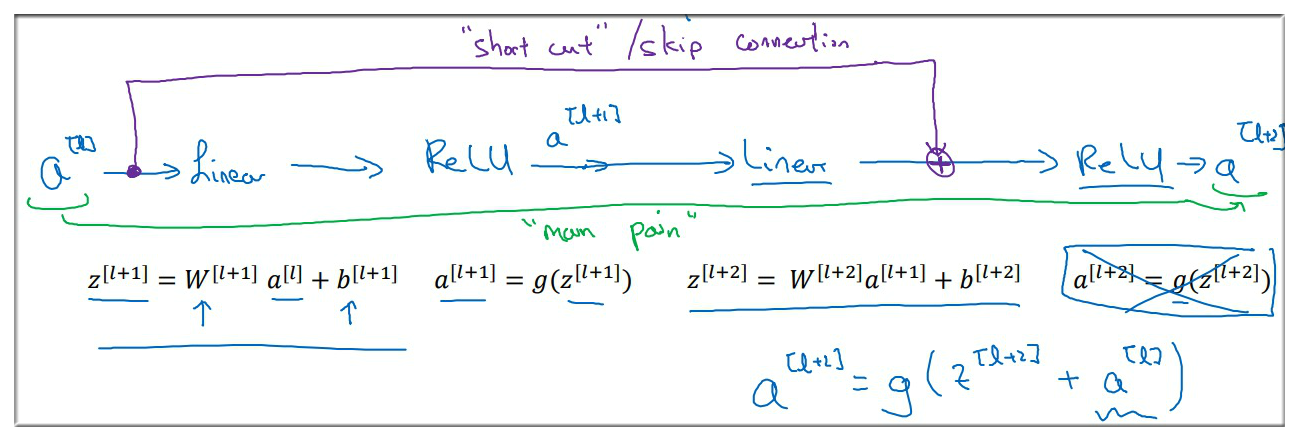
特别注意上图中的紫色线连接, 通过这条线直接将数据传递给 , 所以 ,这条紫色线也叫作short cut(或skip connection)
3.2 残差网络
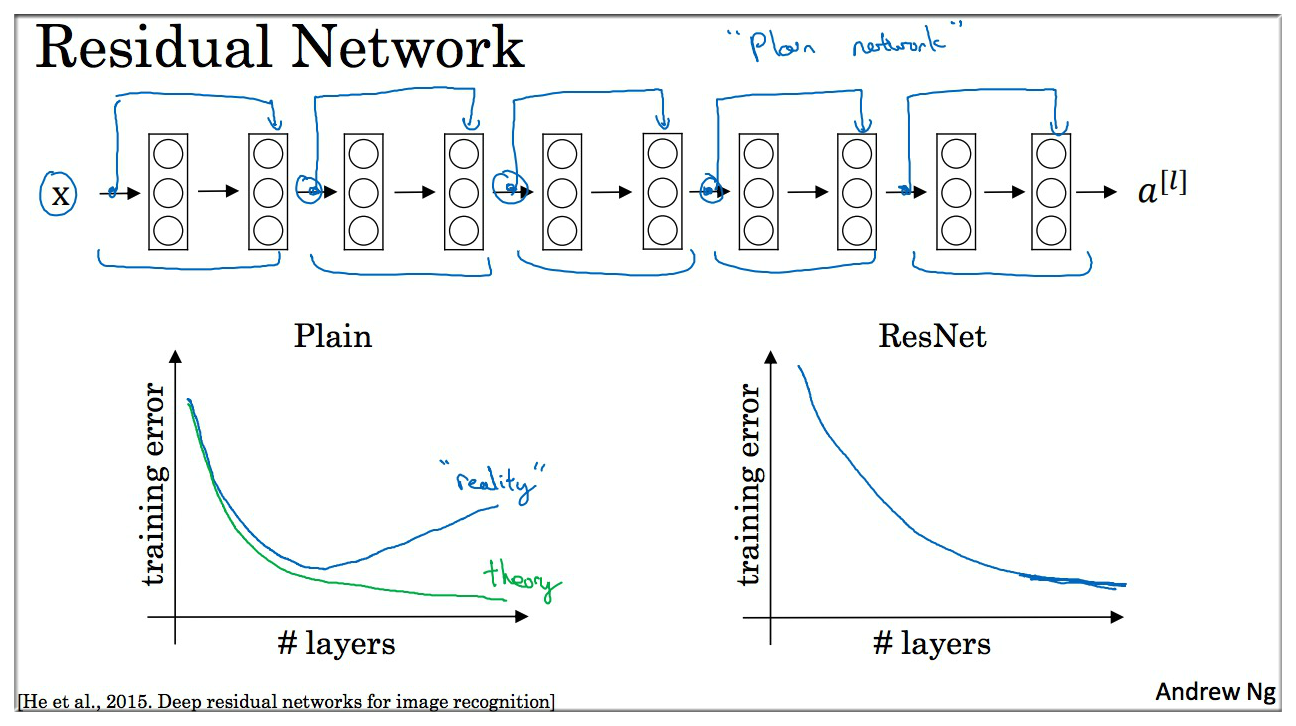
如图示,残差网络每两层网络节点组成一个残差块,这也就是其与普通网络(Plain Network)的差别。
随着网络深度的加深,优化算法会越来越难训练,训练错误会越来越多,但是有了 ResNets 就不一样了. 也可以在一定程度上缓解梯度消失和梯度爆炸问题. 另一角度,网络越深会比较臃肿,但是 ResNet 确实在训练深度网络方面非常有效.
结合之前的课程我们知道如果使用普通网络训练模型,训练误差会随着网络层次加深先减小,而后会开始增加,而残差网络则不会有这种情况,反而它会随着层次增加,误差也会越来越小,这与理论相符。
随着网络深度的加深,优化算法会越来越难训练,训练错误会越来越多,但是有了 ResNets 就不一样了. 也可以在一定程度上缓解梯度消失和梯度爆炸问题. 另一角度,网络越深会比较臃肿,但是 ResNet 确实在训练深度网络方面非常有效.
4. Why ResNets work
吴大表示: 网络在训练集上表现好,才能 Hold-out 交叉验证集 或 dev集、测试集上表现好,所以训练集上表现好是第一步.
为了直观解释残差网络为什么有用,假设我们已经通过一个很大的神经网络得到了 。 而现在我们又需要添加两层网络进去,我们看看如果添加的是残差块会有什么效果。如下图示:
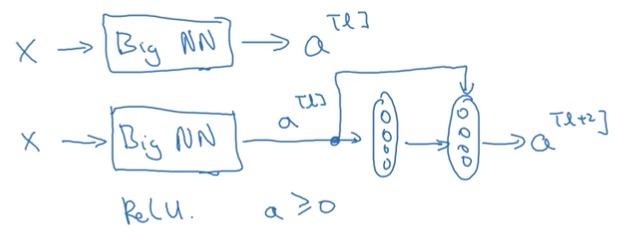
由 残差块Residual Block 的特点我们知道
我们先考虑一个极端情况,即 , 那么 (因为激活函数是Relu),所以在添加了额外的两层网络后,即使最坏情况也是保持和之前结果一样。(而如果只是加上普通的两层网络,可能结果会更好,但是也很有可能结果会越来越糟糕, 因为普通网络就算是选择用来学习恒等函数的参数都很困难),残差网络起作用的主要原因是这些残差块学习恒等函数非常容易, 这也就是为什么残差网络能够保证深度网络依旧有用的原因了。
注意 : 各层网络的维度,因为 , 那么就要求 要和 保持相同的维度所以残差网络使用的是Same卷积。
但是如果唯独不一样也没关系,可以给 乘上一个 来保持相同维度。 的值可以通过学习获得
普通网络 和 ResNets 常用的结构是 Conv -> Conv -> Conv -> Pool -> Conv -> Conv -> Conv -> Pool 依次重复之… 直到有一个通过 Softmax 进行预测的全连接层.
5. in Network and 1×1 convolutions
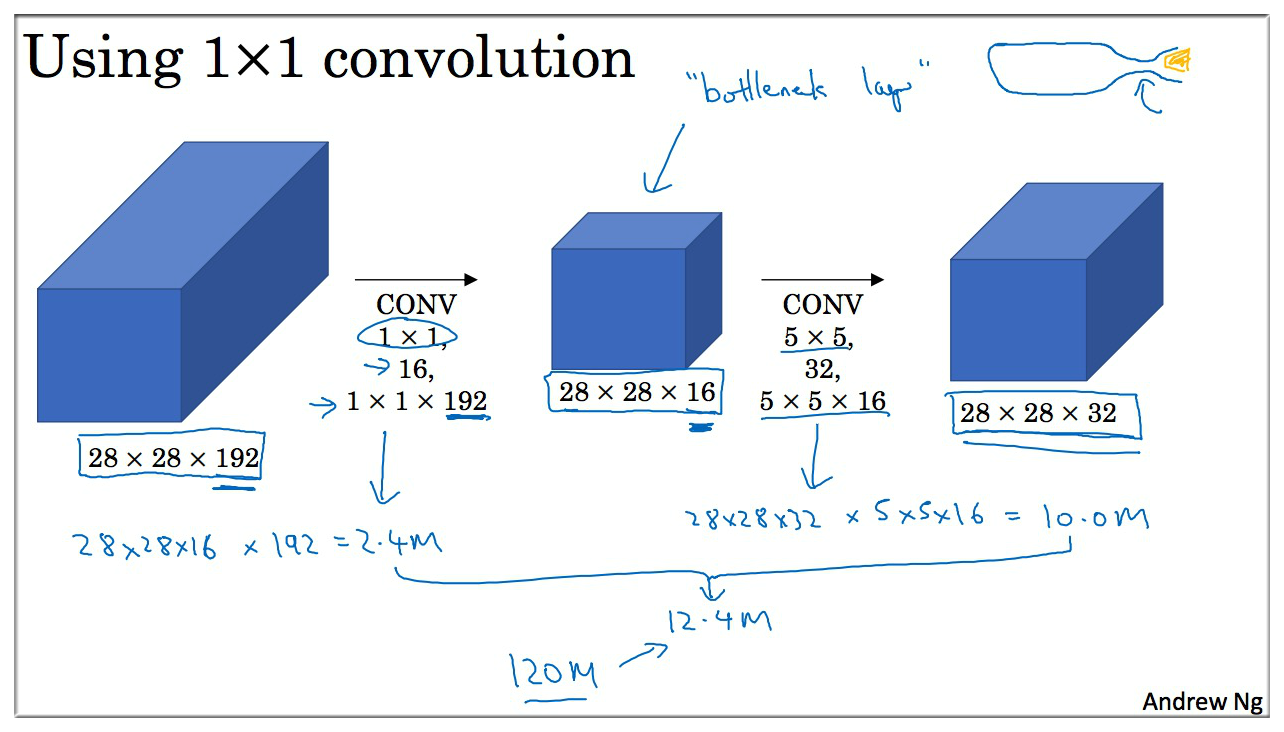
1 \* 1 卷积乍看起来好像很没用,如下图上,但是如果这个 1 \* 1 的卷积有深度呢?
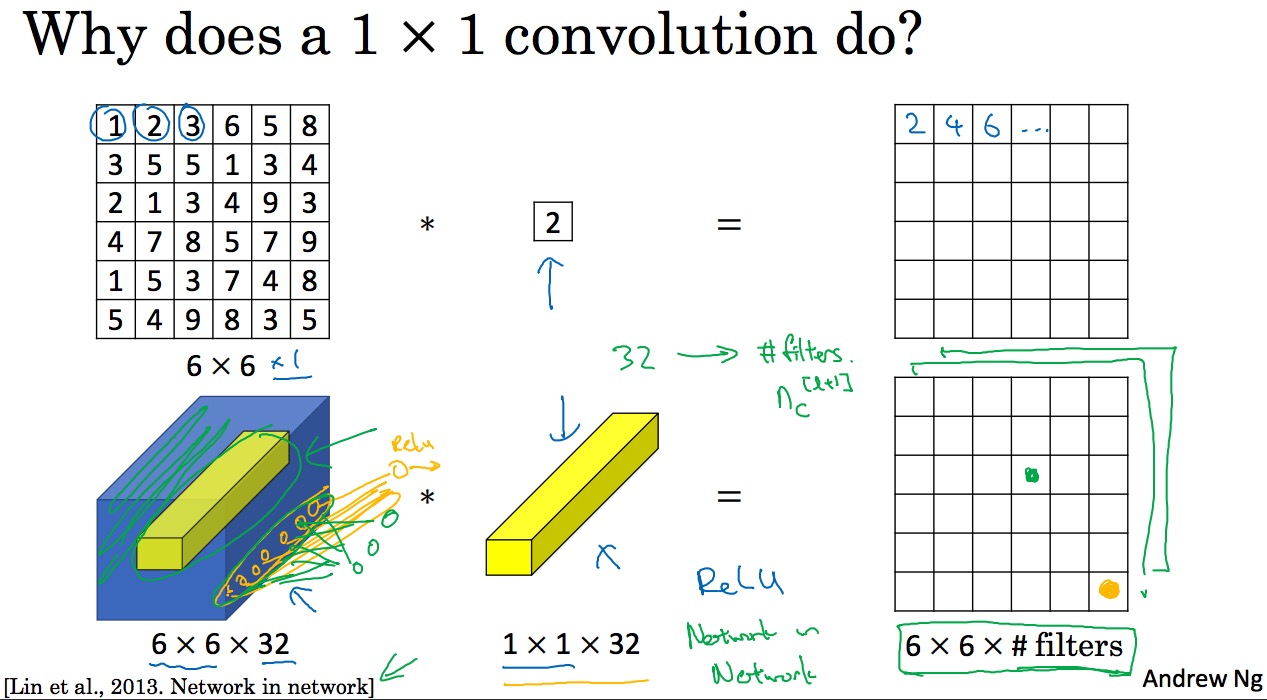
说个更加直观的理解就是使用 1\*1 卷积可以很方便的减少深度,而不改变高度和宽度,如下图所示:
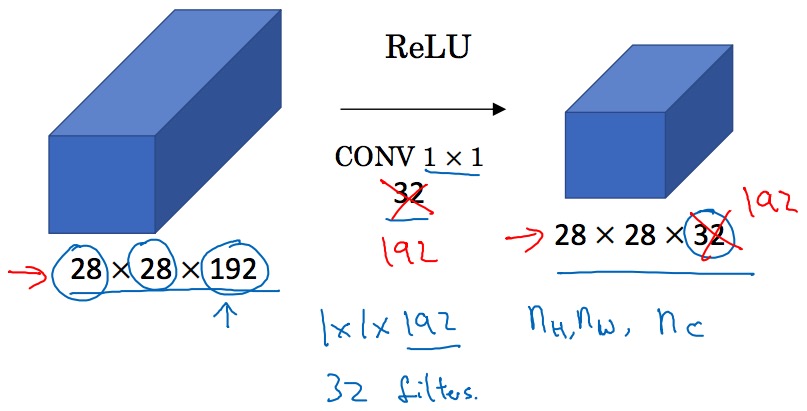
只需要用 32 个 (1\*1\*192) 的 Filter 即可, 如果不用 1 \* 1 卷积,例如采用 2\*2 卷积,要想实现只改变深度,那么还需要使用 padding,相比起来更加麻烦了.
6. Inception network motivation
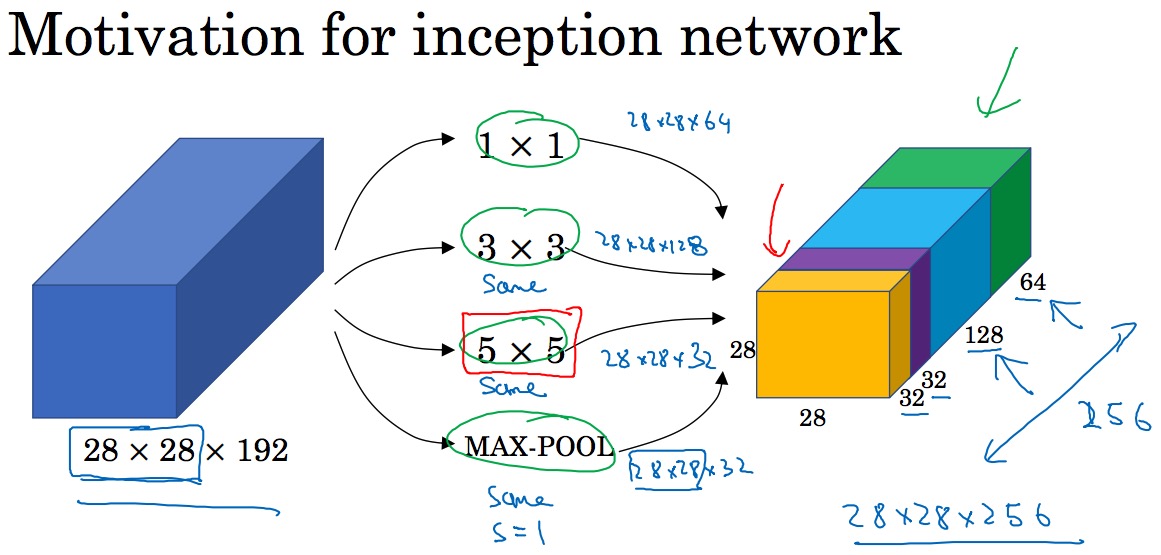
如上图示,我们使用了各种过滤器,也是用了 Max Pooling。但是这些并不需要人工的选择其个数,这些都可以通过学习来确定下来。所以这种方法很好的帮助我们选择何种 Filter 的问题,这也就是 Inception网络。
6.1 计算成本
注意随之而来的计算成本,尤其是 5\*5 的 Filter,下面以这个 Filter 举例进行说明:
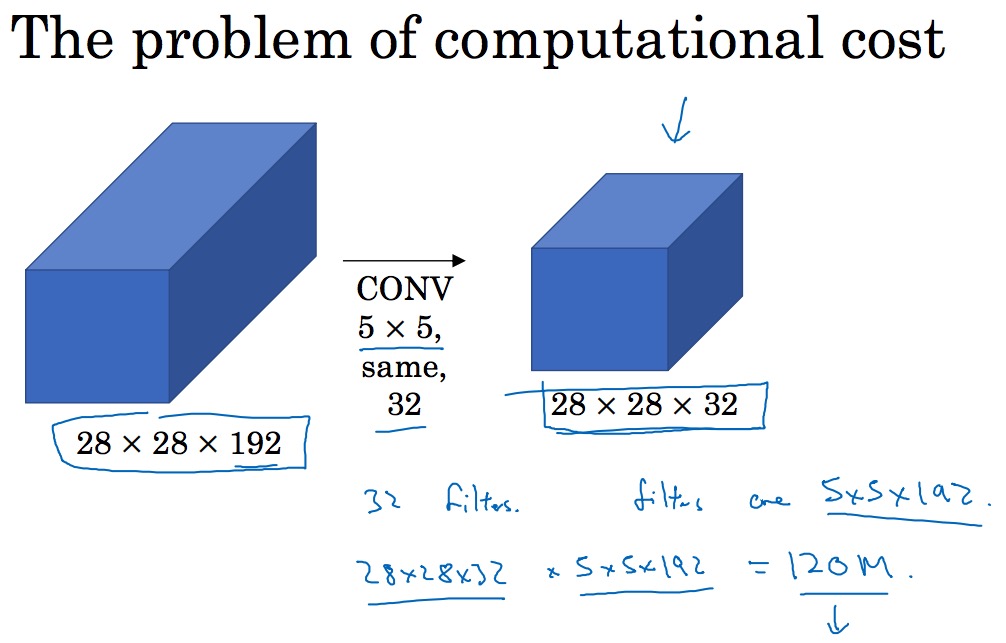
如上图示,使用 32 个 (5\*5\*192) 的 Filter,对 进行 Same卷积 运算得到 的输出矩阵,该卷积需要执行的乘法运算有多少次呢?
输出矩阵中的一个数据是经过 (5\*5\*192) 次乘法得到的,那么总共的乘法运算次数则是 (5\*5\*192\*28\*28\*32=1.2) 亿
6.2 瓶颈层(Bottleneck layer)
上面运算次数多大1.2亿次,运算量相当大,因此有另一种网络结构对此进行优化,且可以达到同样效果,即采用 1 * 1 卷积
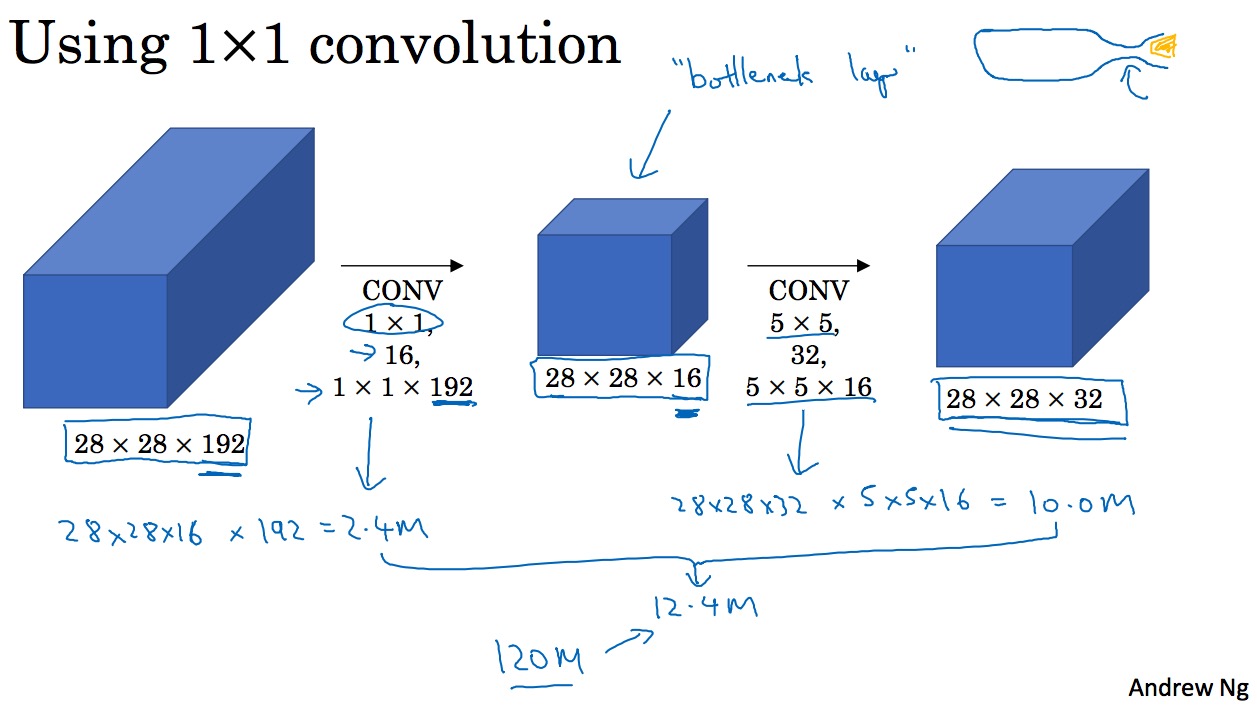
如图示进行了两次卷积,我们计算一下总共的乘法次数。
第一次卷积:28 * 28 * 16 * 192 = 2.4 million
第二次卷积:28 * 28 * 32 * 5 * 5 * 16 = 10 million
总共乘法次数是 12.4 million,这与上面直接用 5 * 5 Filter 的运算次数整整少了十倍。
7. Inception network
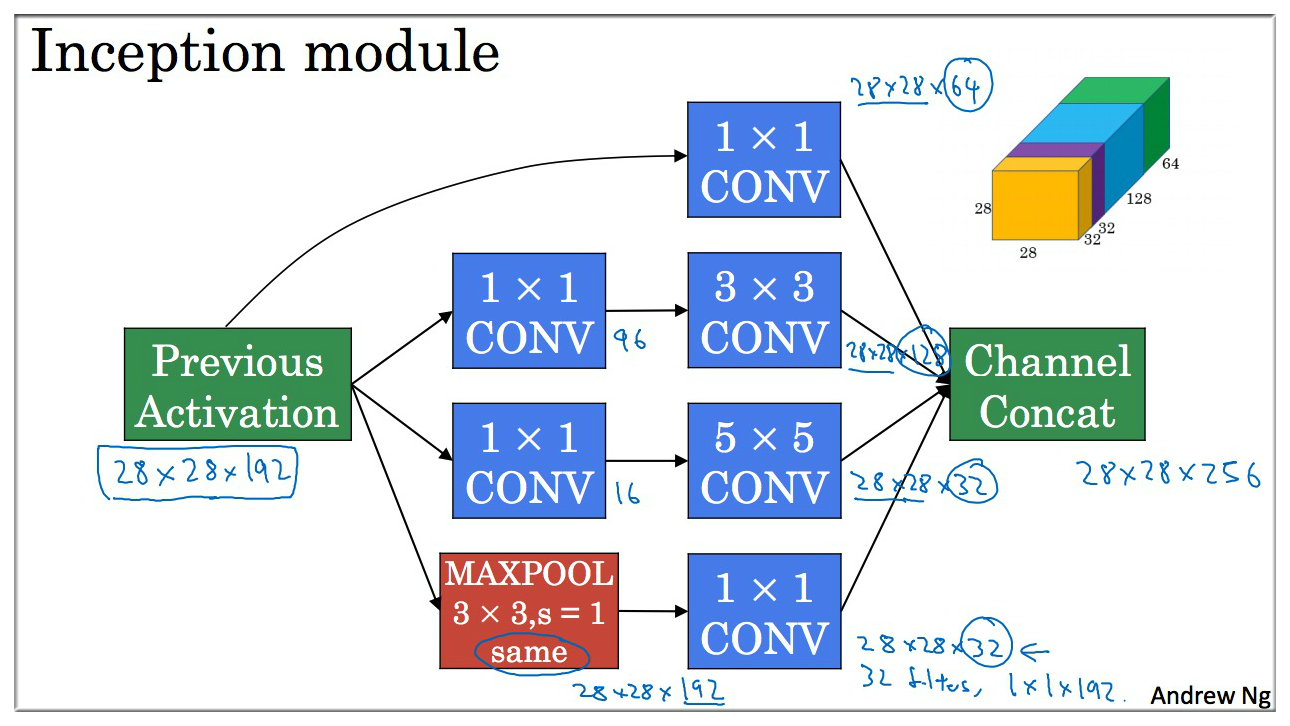
为了可以防止过拟合,还有个特别的 inception network,是一个 Google 员工开发的叫做 GoogLeNet,这个名字是为了向 LeNet 致敬. 这样非常好,深度学习的研究人员如何重视协作,深度学习工作者对彼此的工作成果,都有一种强烈的敬意.
8. Using open-source impl
Practical advice for using ConvNets
9. Transfer Learning
简单说就是在他人的基础上实现自己想要的模型,举个🌰,假如我们现在需要识别家里养的两只猫,分别叫 小花 和 小白,但是我们只有比较少的图片。幸运的是网上已经有一个已经训练好的模型,是用来区分1000个不同事物的(包括猫),其网络模型如下:

我们的需求是最后结果有三种:是 小花,or 小白,or 都不是。所以需要对 softmax 做如下图修改.
由于数据较少,所以可以对他人的模型的前面的结构中的参数进行冻结,即 权重 weight 和 偏差 bias 不做改动。
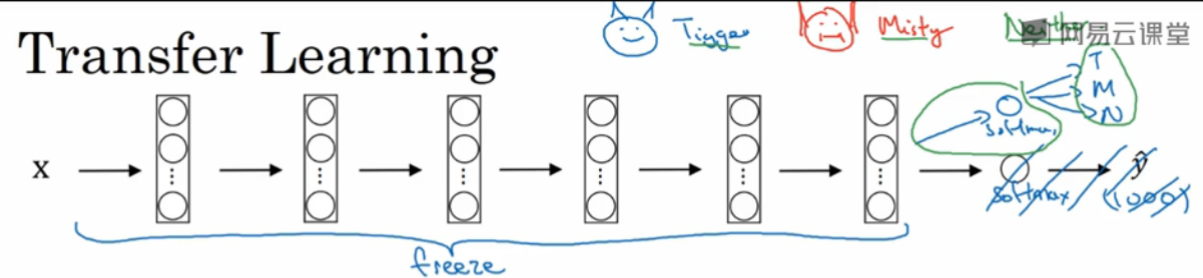
当然,如果我们有一定量的数据,那么 freeze 的范围也可以随之减少,即拿来训练的层次可以增多

you find that for a lot of computer vision applications, you just do much better if you download someone else’s open source weights and use that as initialization for your problem.
I think that computer vision is one where transfer learning is something that you should almost always do. (unless you actually have a very very large data set…)
10. Data augmentation
10.1 Common augmentation
- 旋转(rotation)
- 修剪(shearing)
- 局部变形(local warping)
- 镜像(mirroring)
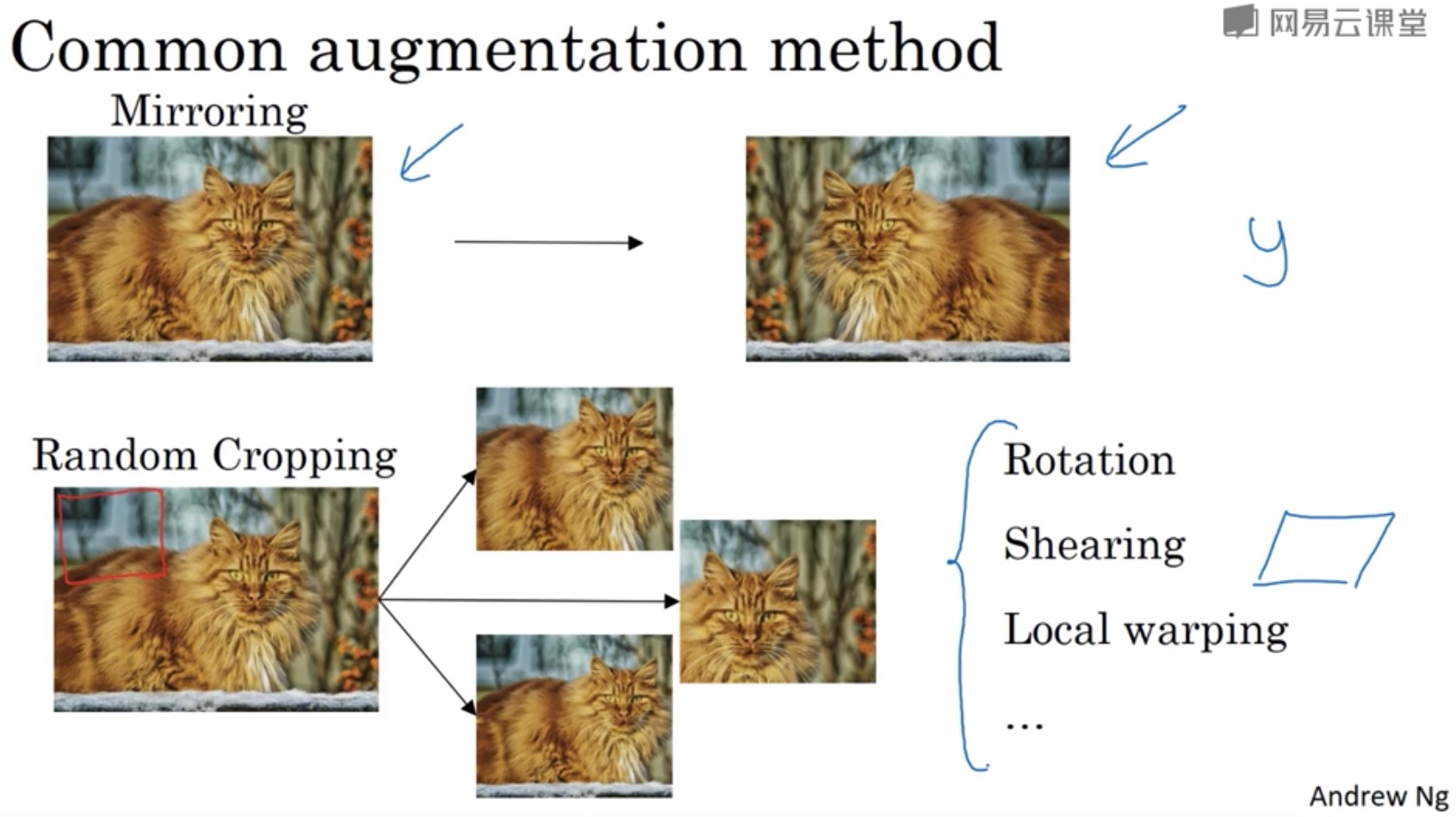
以上介绍的方法,同时使用并没有什么坏处,但是在实践中,因为太复杂了,所以使用的很少。
更经常使用的方法可能下面要介绍的 Color shifting 。
10.2 Color shifting
我们都知道图像是由 RGB 三种颜色构成的,所以该数据扩充方法常采用 PCA color augmentation,即假如一个图片的 R 和 G 成分较多,那么该算法则 R,G 的值会减少很多,而 B 的值变化会少一些,所以使得总体的颜色保持一致.
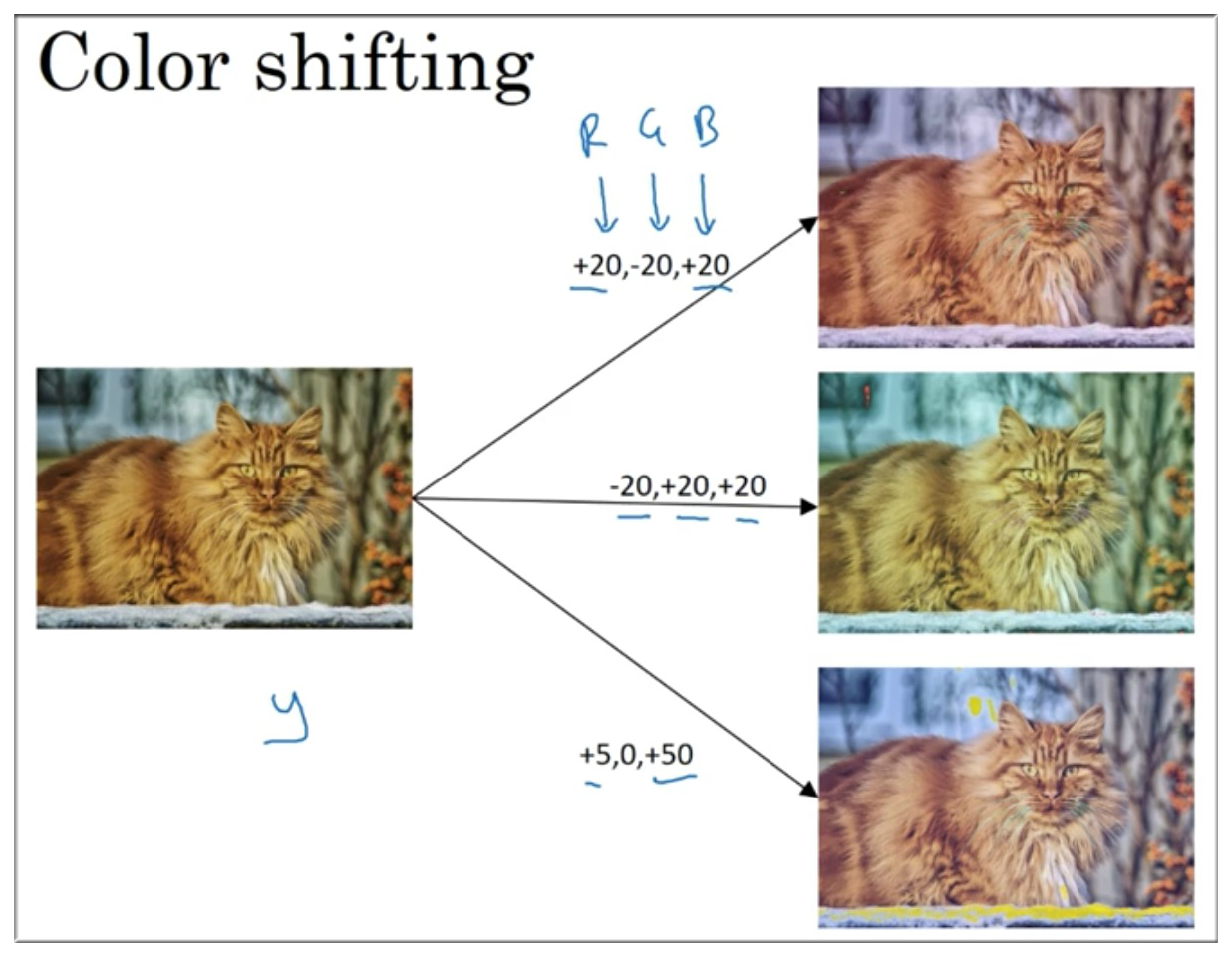
如果你看不懂这些,那么没关系,可以看看 AlexNet 论文中的细节,你也能找到 PCA 颜色增强的开源实现方法.
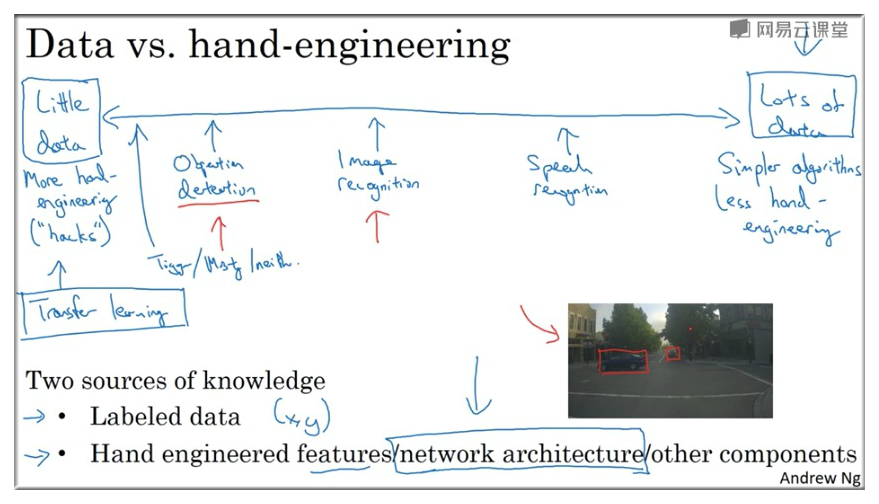
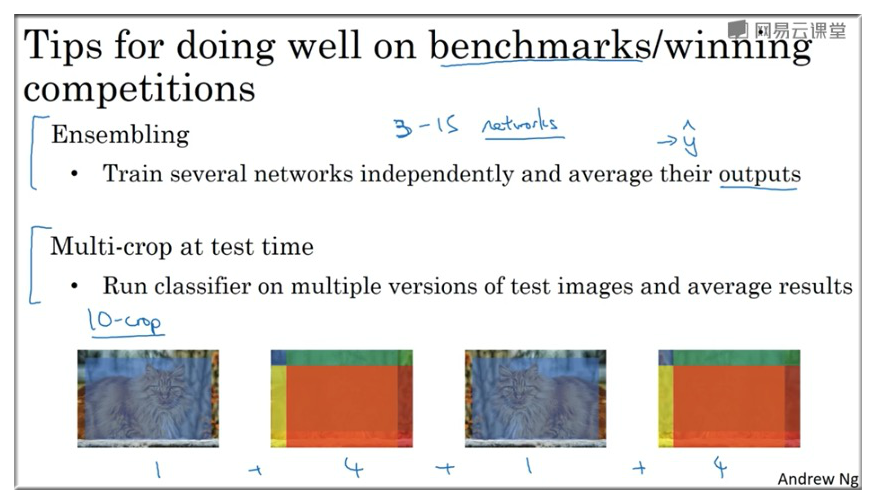
11. The state of CV

Checking if Disqus is accessible...