Fine-grained Sentiment Analysis of User Online Reviews
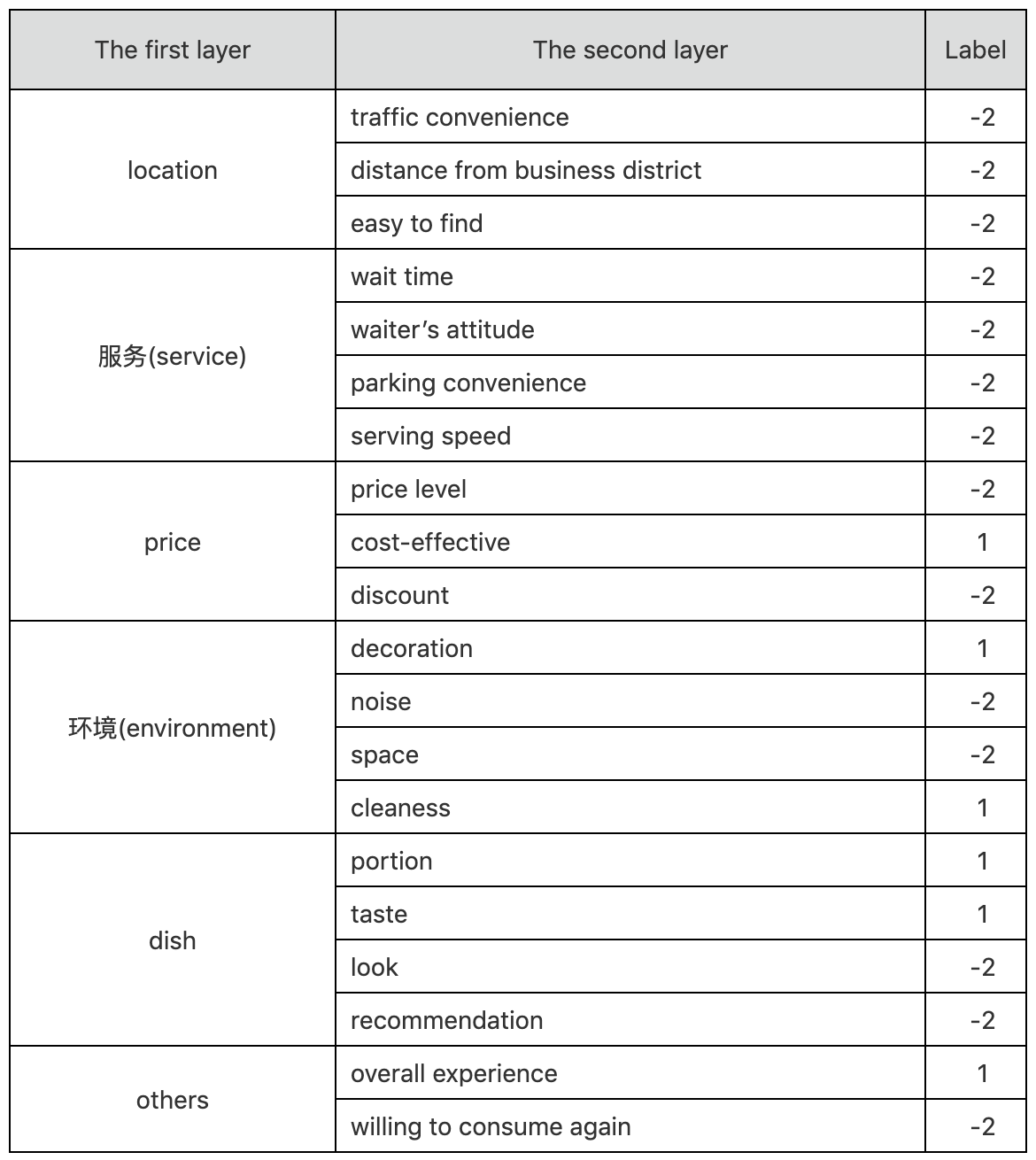
Online reviews have become the critical factor to make consumption decision in recent years. They not only have a profound impact on the incisive understanding of shops, users, and the implied sentiment, but also have been widely used in Internet and e-commerce industry, such as personalized recommendation, intelligent search, product feedback, and business security. In this challenge, we provide a dataset of user reviews for fine-grained sentiment analysis from the catering industry, containning 335K public user reviews from Dianping.com. The dataset builds a two-layer labeling system according to the granularity, which contains 6 categories and 20 fine-grained elements.
Training set: 105K
Verification set: 15K
Test set A: 15K
Test set B: 200K
There are four sentimental types for every fine-grained element: Positive, Neutral, Negative and Not mentioned, which are labelled as 1, 0, -1 and-2. The meaning of these four labels are listed below.

An example of one labelled review:
“味道不错的面馆,性价比也相当之高,分量很足~女生吃小份,胃口小的,可能吃不完呢。环境在面馆来说算是好的,至少看上去堂子很亮,也比较干净,一般苍蝇馆子还是比不上这个卫生状况的。中午饭点的时候,人很多,人行道上也是要坐满的,隔壁的冒菜馆子,据说是一家,有时候也会开放出来坐吃面的人。“
「AI Challenger」是面向全球人工智能人才的开源数据集和编程竞赛平台。AI Challenger 2018 由创新工场、搜狗、美团点评、美图公司联合主办。有上万支团队参赛, 覆盖 81 个国家、1100 所高校、990 家公司。
min_count设置为2貌似也有一些负向影响, word_ngrams 2, epoch 10 .
1.3 baseline 效果
1 | service_wait_time:0.5247890022873511 |
调参:
1 | python main_train.py -mn fasttext_model_wn2.pkl -wn 2 |
约跑15分钟左右,存储的模型大约在17G,验证集 macro F1值结果如下:
1 | service_wait_time:0.5247890022873511 |
这个结果看起来还不错,我们可以基于这个fasttext多分类模型进行测试集的预测:
1 | python main_predict.py -mn fasttext_wn2_model.pkl |
优化方法: 去停用词和去一些标点符号,调参,learning_rate的影响是比较直接的,min_count
1.4 fastText 速度快
能够做到效果好,速度快,主要依靠两个秘密武器:
- 利用了 词内的n-gram信息 (subword n-gram information)
- 用到了 层次化Softmax回归 (Hierarchical Softmax) 的训练 trick.
2. Attention RNN、RCNN
2.1 预处理 data
粗暴使用char模型,用到的停用词也不多。
- trainsets lines: 501132, 合法例子 : 105000
- validationset lines: 70935, 合法例子 : 15000
- testsets lines: 72028, 合法例子 : 15000
数据预处理,生成 train_char.csv、test_char.csv、test_char.csv 三个文件:
1 | -rw-r--r-- 1 blair 10:36 test_char.csv |
word2vec: 维度 100, 窗口 10, 过滤掉次数小于 1~2 的字
1 | 3.1M chars.vector |
过滤掉低频词之后:
1 | word2vec/chars.vector 为 7983 * 100 |
2.2 Attention RCNN
Attention-RNN (0.637)、Attention-RCNN (0.669)
- Attention 参考自 Kaggle 的 Attention Model
Kaggle 常见文本分类结构: 2层GRU 接Attention层,然后和 avgpool、maxpool concat 接起来.
1 | def model(self, embeddings_matrix, maxlen, word_index, num_class): |
为了之后 summary 看清楚网络结构,所以我们一些参数先写死看一下:
1 | import keras |
接下来:
1 | x_3 = encode(x_4) |
RNN:
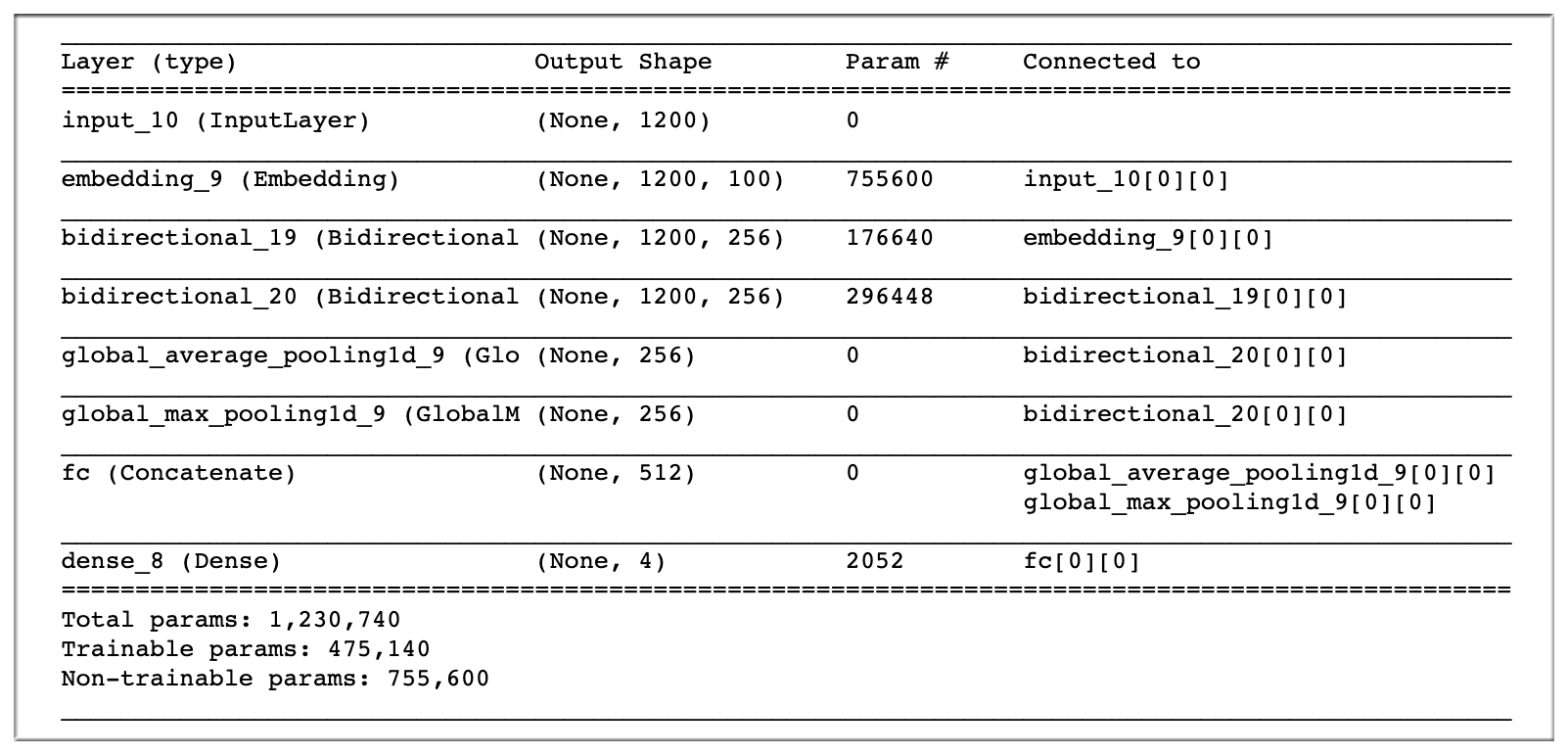
RCNN:
1 | x_4 = Embedding(7555+ 1,#7983+1 # 词汇表大小, 即,最大整数 index + 1 |
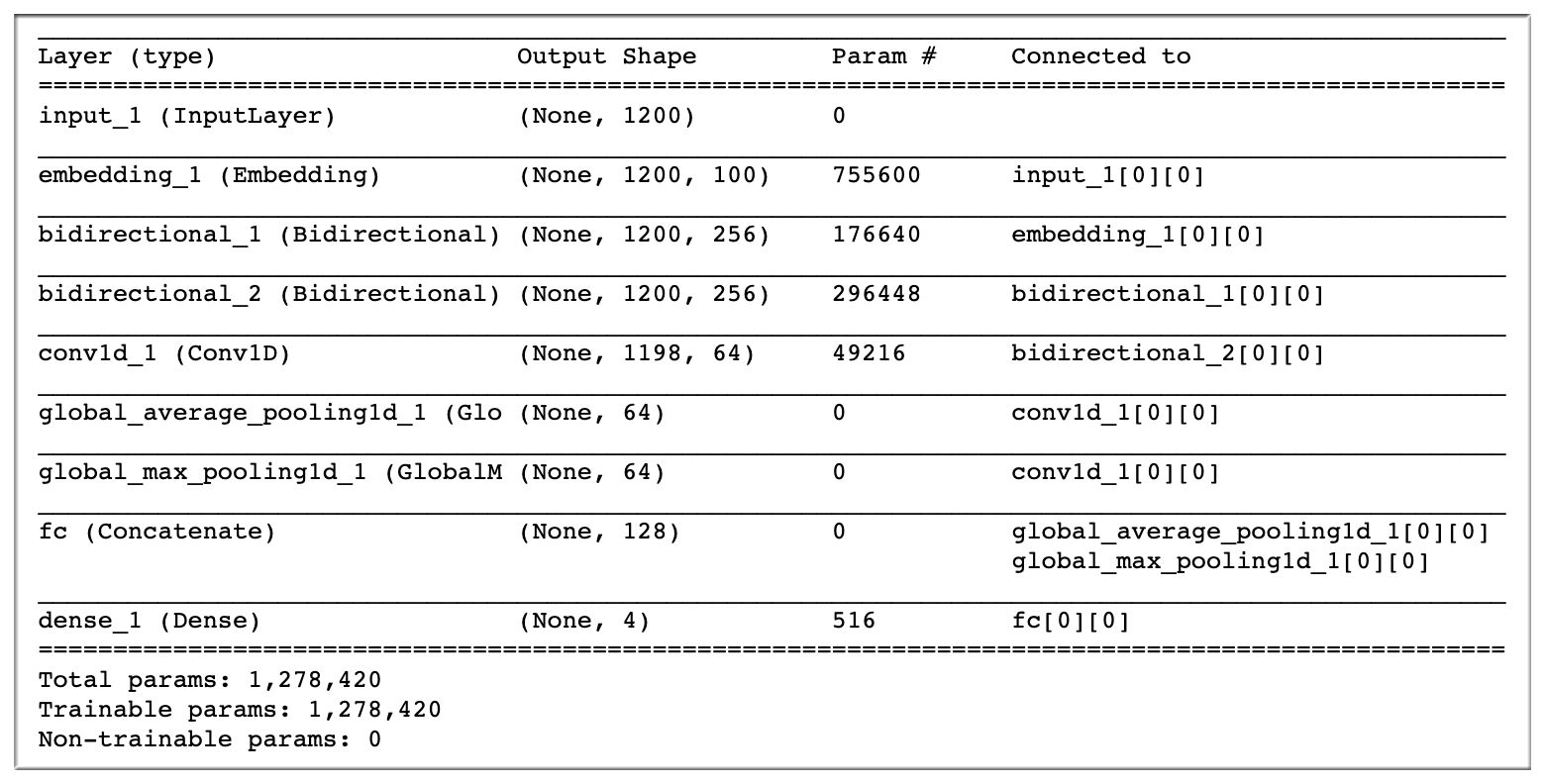
Input 一个网络层次,输入层 在 keras
SpatialDropout1D ,那么常规的 dropout 将无法使激活正则化,且导致有效的学习速率降低。
SpatialDropout1D ,在这种情况下,SpatialDropout1D 将有助于提高特征图之间的独立性,应该使用它来代替 Dropout。CuDNNGRU 是 基于CuDNN的快速GRU实现,只能在GPU上运行,只能使用 tensoflow 为后端
CuDNNLSTM 是 基于CuDNN的快速LSTM实现,只能在GPU上运行,只能使用 tensoflow 为后端attention = Attention(maxlen)
Embedding嵌入层将正整数(下标)转换为具有固定大小的向量,如[4, [20]]->[[0.25, 0.1], [0.6, -0.2]]
1 | keras.layers.embeddings.Embedding( |
Embedding 的一些参数解释:
Embedding层只能作为模型的第一层
input_dim: int > 0。词汇表大小, 即,最大整数 index + 1。
output_dim: int >= 0。词向量的维度。
embeddings_initializer: 嵌入矩阵的初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
input_length:当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
Convolutional Neural Networks (week1) - CNN , 运用 Padding
TensorFlow中CNN的两种padding方式“SAME”和“VALID”
word2vec : 7983 100 word2vec/chars.vector 过滤掉低频词
循环卷积神经网络(RCNN),并将其应用于文本分类的任务。首先,我们应用一个双向的循环结构,与传统的基于窗口的神经网络相比,它可以大大减少噪声,从而最大程度地捕捉上下文信息。此外,该模型在学习文本表示时可以保留更大范围的词序。其次,我们使用了一个可以自动判断哪些特性在文本分类中扮演关键角色的池化层,以捕获文本中的关键组件。我们的模型结合了RNN的结构和最大池化层,利用了循环神经模型和卷积神经模型的优点。此外,我们的模型显示了O(n)的时间复杂度,它与文本长度的长度是线性相关的。
- RNN 优点: 最大程度捕捉上下文信息,这可能有利于捕获长文本的语义。
- RNN 缺点: 是一个有偏倚的模型,在这个模型中,后面的单词比先前的单词更具优势。因此,当它被用于捕获整个文档的语义时,它可能会降低效率,因为关键组件可能出现在文档中的任何地方,而不是最后。
- CNN 优点: 提取数据中的局部位置的特征,然后再拼接池化层。 CNN可以更好地捕捉文本的语义。是O(n)
- CNN 优点: 一个可以自动判断哪些特性在文本分类中扮演关键角色的池化层,以捕获文本中的关键组件。
首先我们来理解下什么是卷积操作?卷积,你可以把它想象成一个应用在矩阵上的滑动窗口函数。
卷积网络也就是对输入样本进行多次卷积操作,提取数据中的局部位置的特征,然后再拼接池化层(图中的Pooling层)做进一步的降维操作
我们可以把CNN类比N-gram模型,N-gram也是基于词窗范围这种局部的方式对文本进行特征提取,与CNN的做法很类似
1 | from keras.backend.tensorflow_backend import set_session |
2.3 loss function
多分类和多标签分类, gensim训练word2vec及相关函数
多分类:类别数目大于2个,类别之间是互斥的。比如是猫,就不能是狗、猪
categorical crossentropy 用来做多分类问题
binary crossentropy 用来做多标签分类问题
sigmoid,softmax,binary/categorical crossentropy的联系?
Binary cross-entropy 常用于二分类问题,当然也可以用于多分类问题,通常需要在网络的最后一层添加sigmoid进行配合使用
Categorical cross-entropy 适用于多分类问题,并使用softmax作为输出层的激活函数的情况。
2.4 Early Stop
需要在每个 epoch 结束之后去计算模型的 F1 值,这样可以更好的掌握模型的训练情况。
Tips 如果我们在训练中设置 metric 的话,得到是每个 batch 的 F1 值, 是不靠谱的.
类似这样:
1 | def getClassification(arr): |
early_stop,就是在训练模型的时候,当在验证集上效果不再提升的时候,就提前停止训练,节约时间。
2.6 Max Length (padding)
所有评论平均的长度是 200 左右,max_length 取 2 * 200,效果一直不给力.
将 max_length 改为 1200 ,macro f-score 效果明显提升
Tips: 多分类问题中,那些长度很长的评论可能会有部分属于那些样本数很少的类别,padding过短会导致这些长评论无法被正确划分。
Checking if Disqus is accessible...