Transformer to BERT (by Amazon)

Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT的全称是: Bidirectional Encoder Representation from Transformers
1. Transformer to BERT

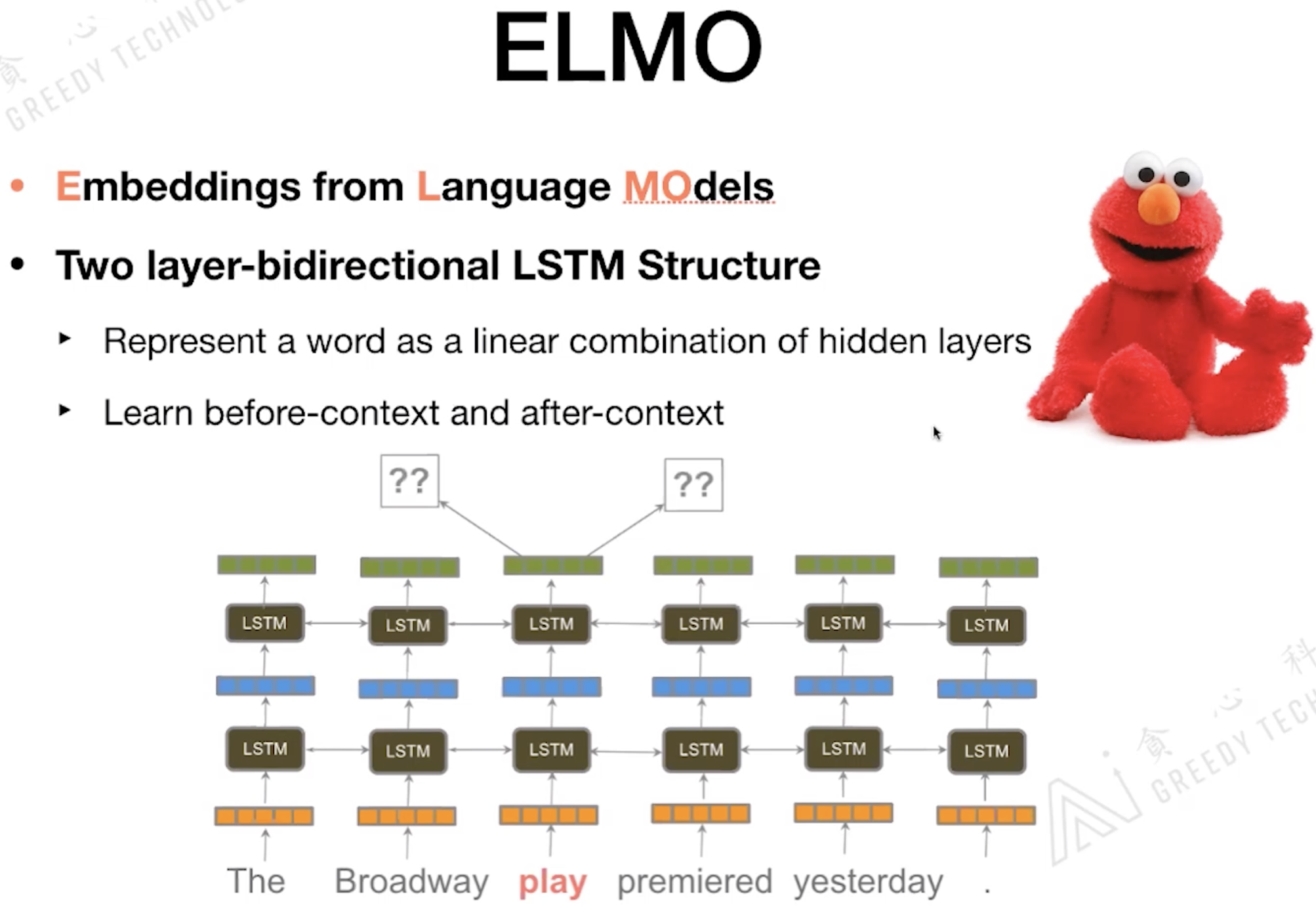
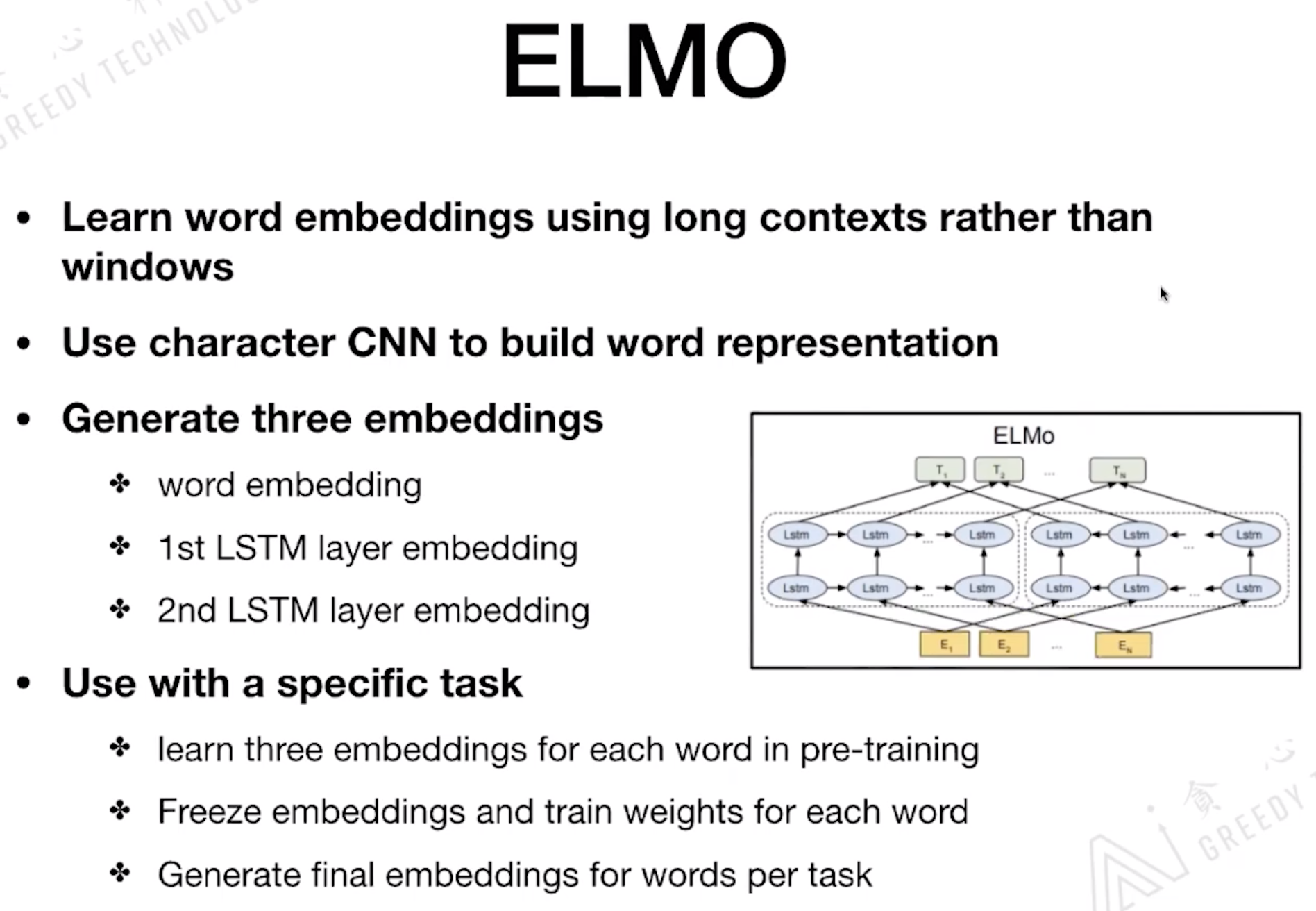
1.1 ELMO
ELMO 全称: Embeddings from Language Models
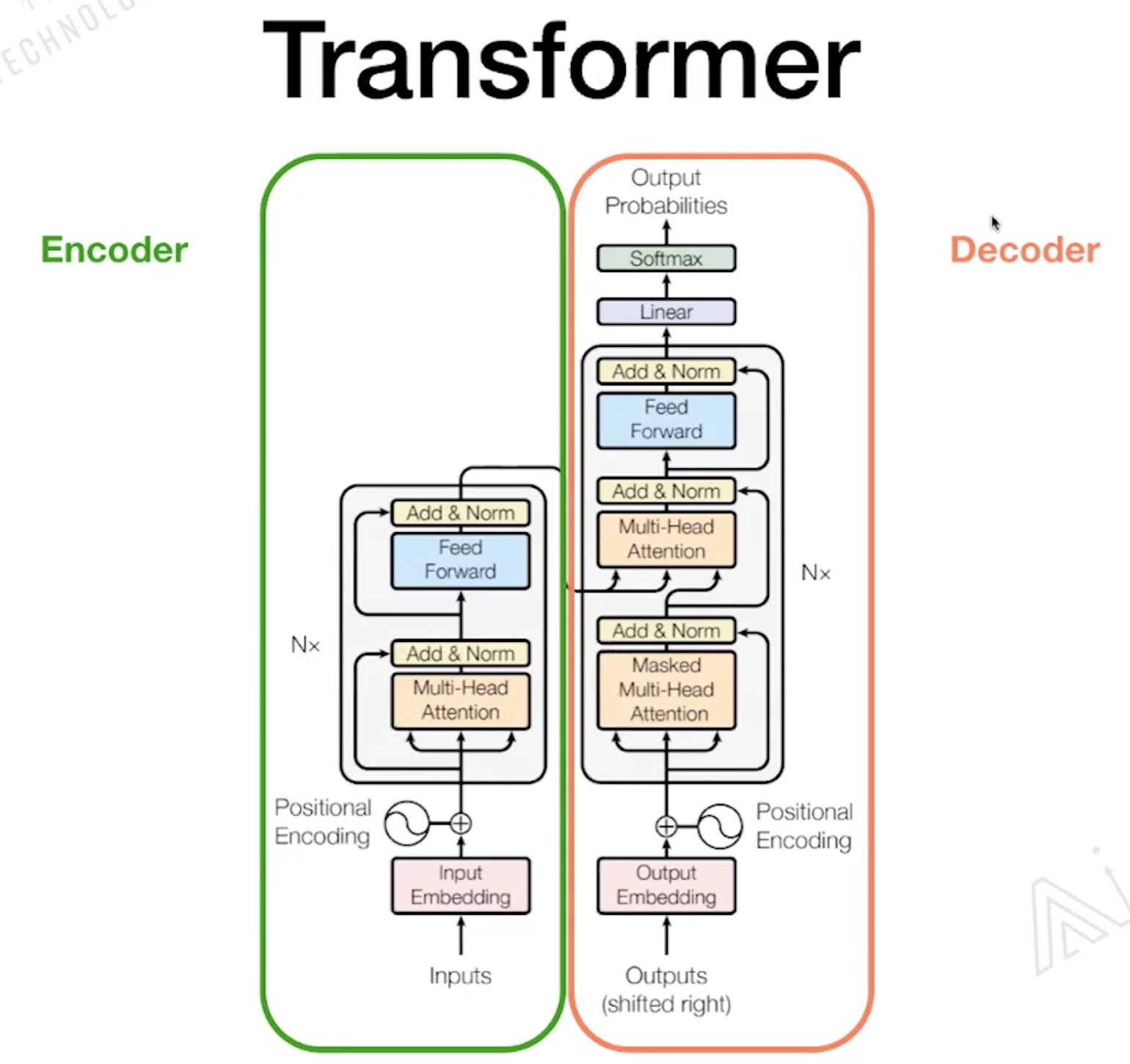
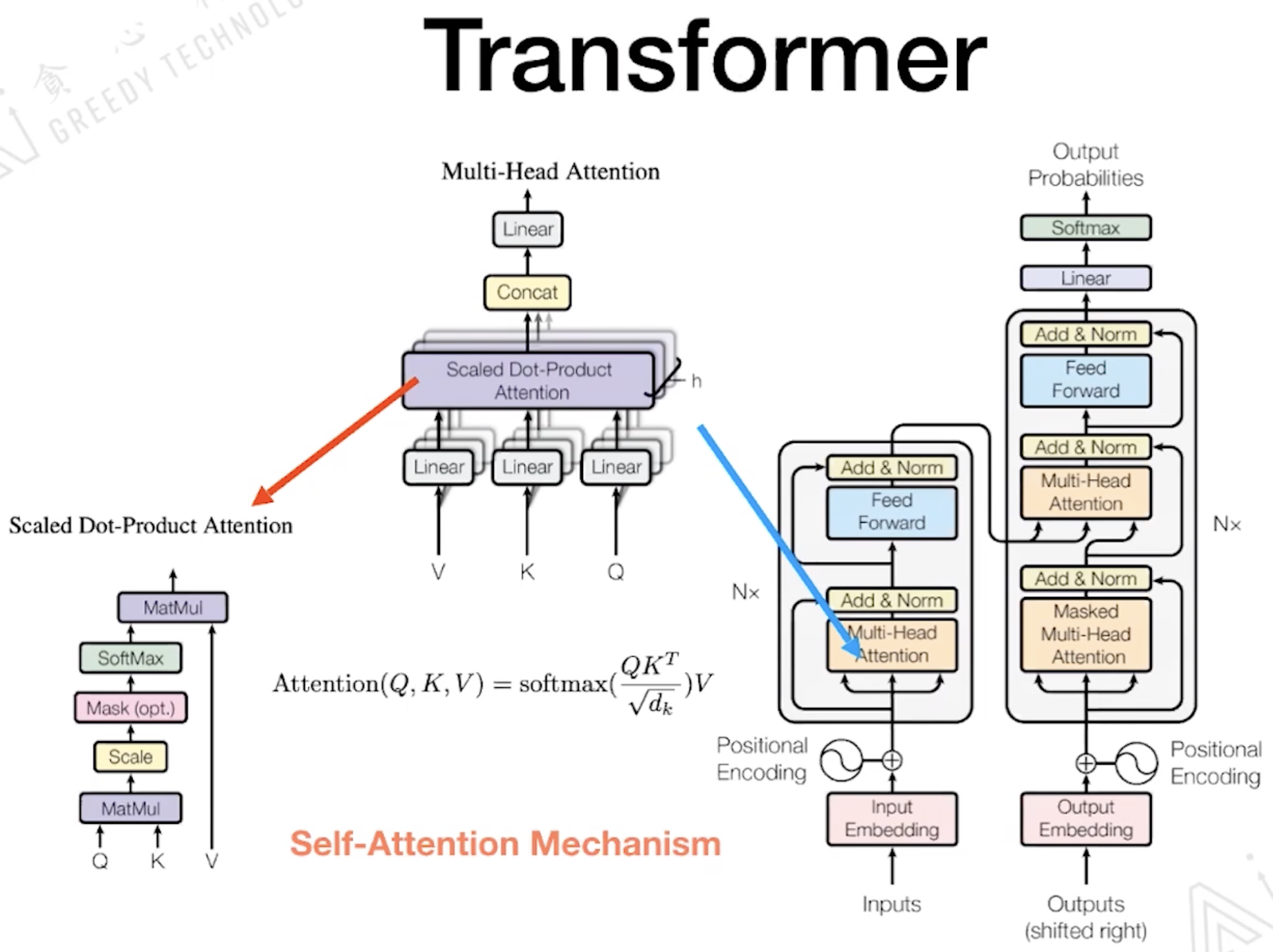
1.2 Transformer
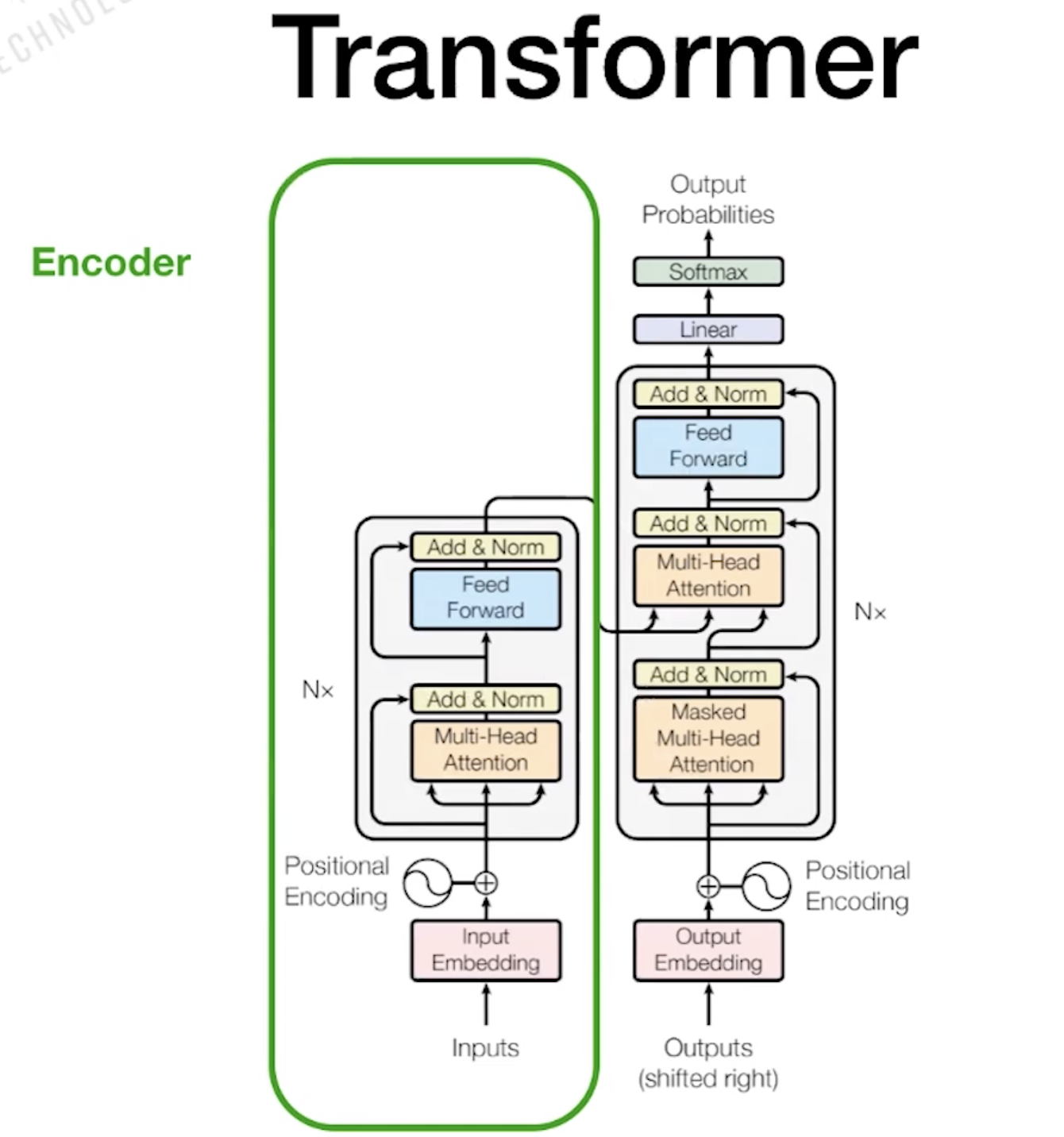
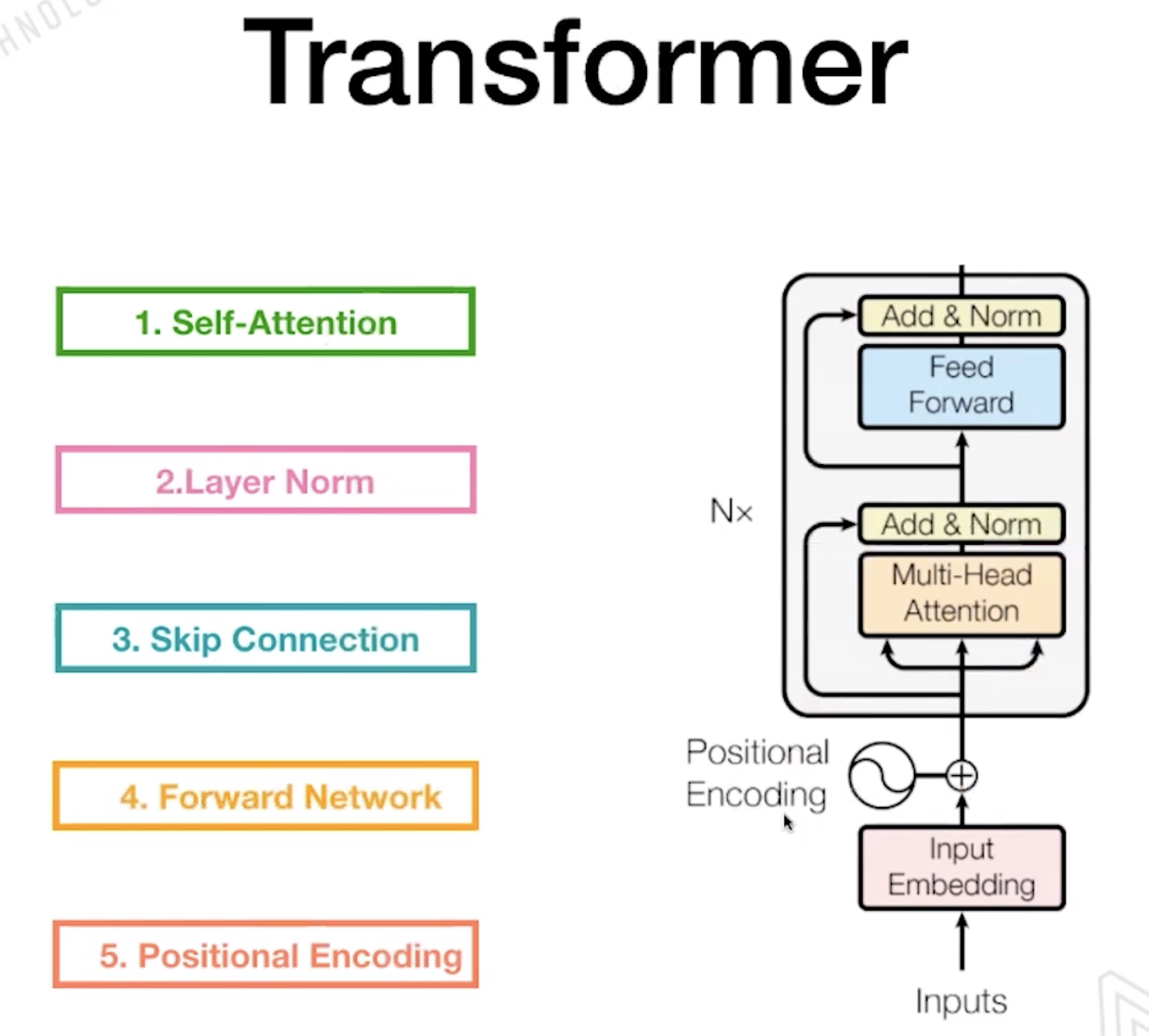
1.3 Bert
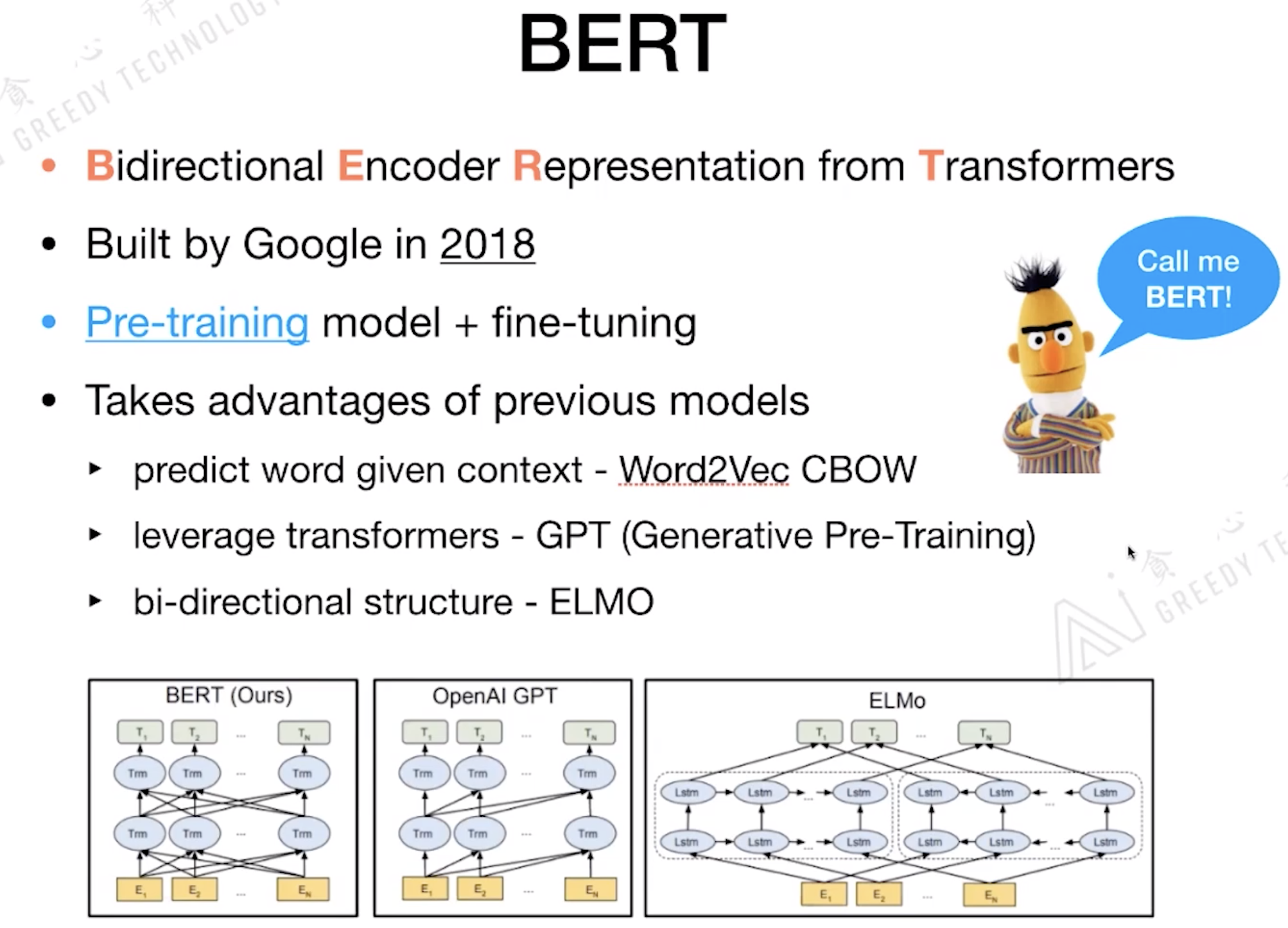
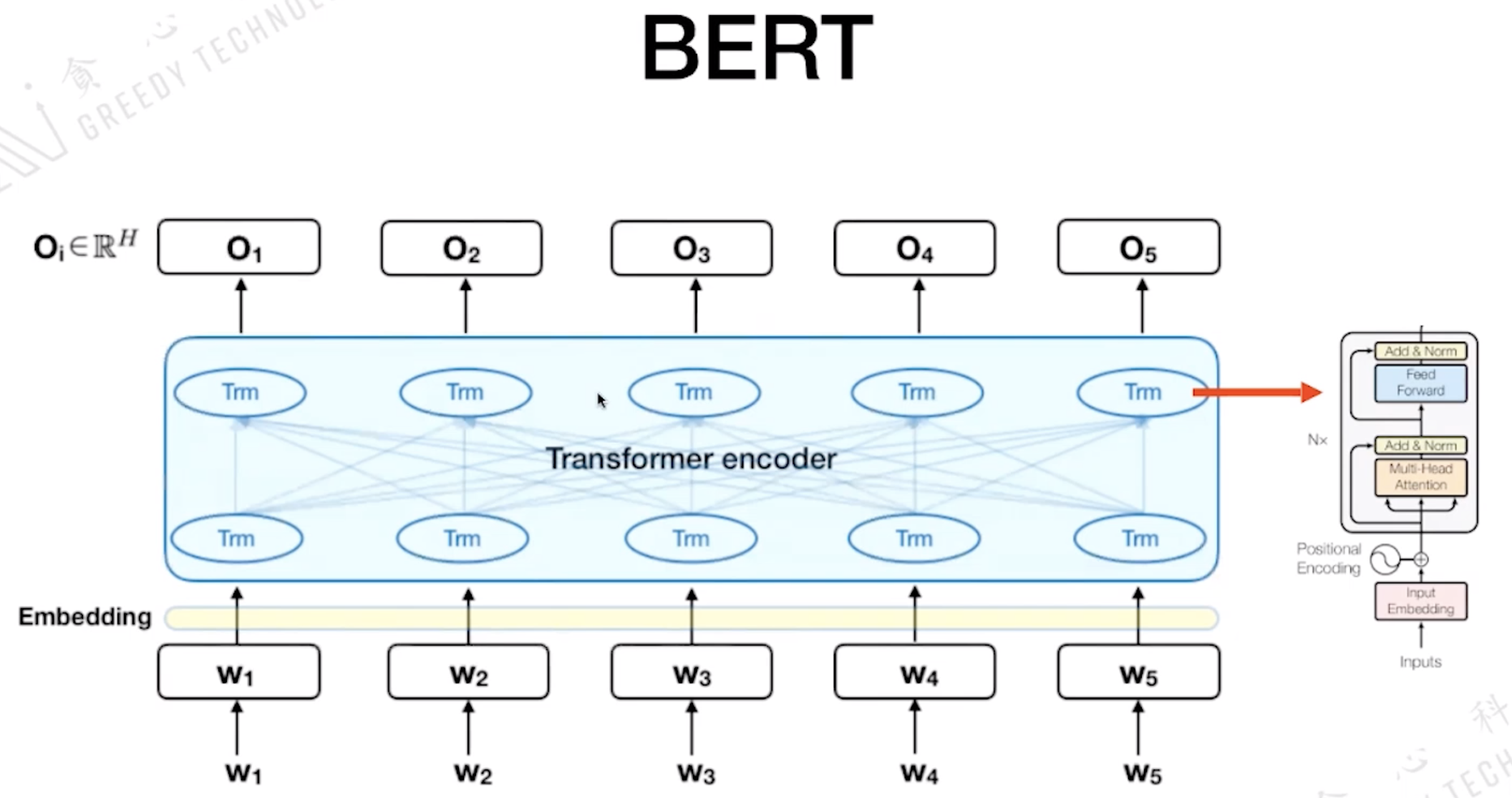
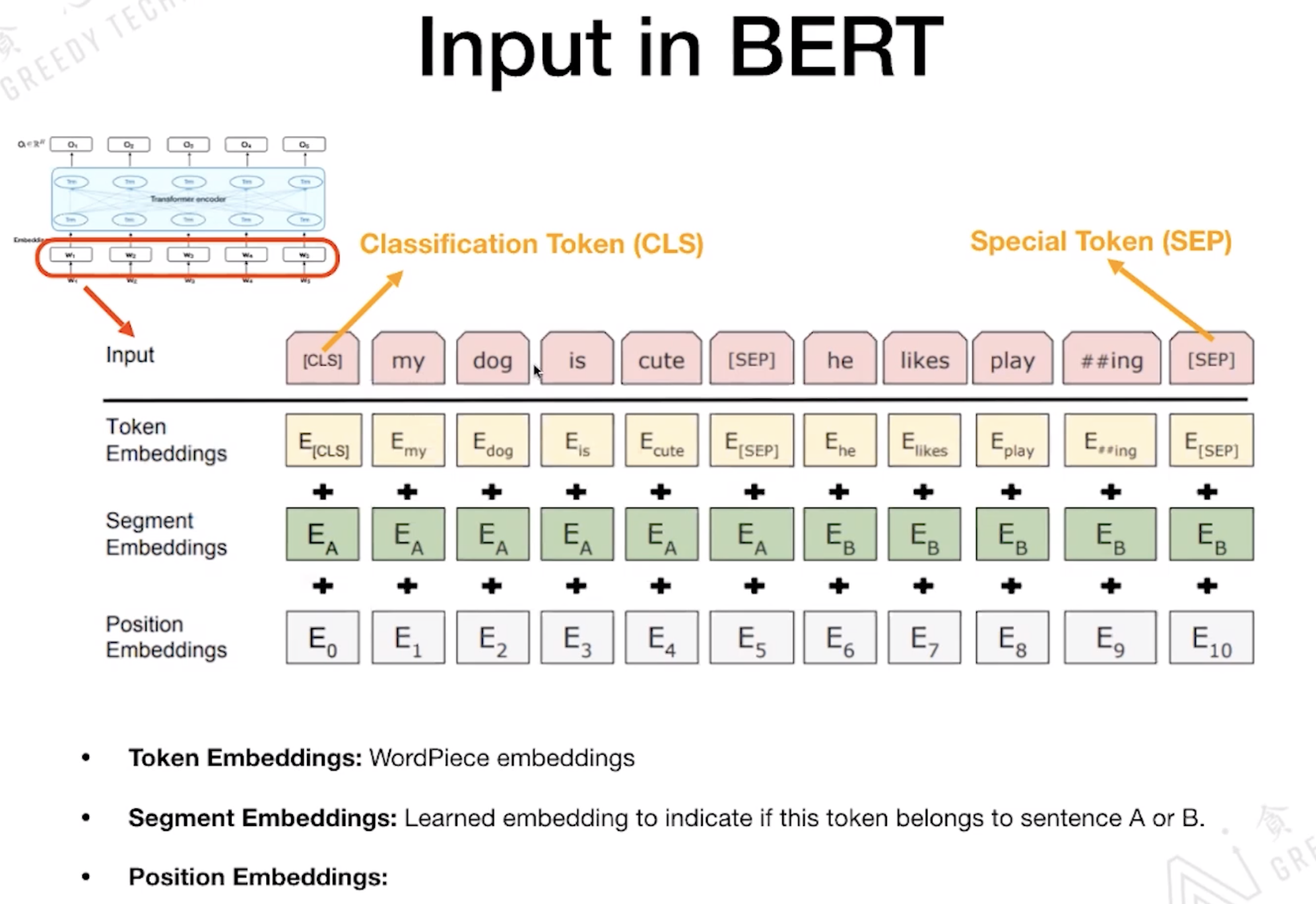
E_A 代表这个 Token 属于 SentenceA 还是 Sentence B
1.4 Pre-training Bert




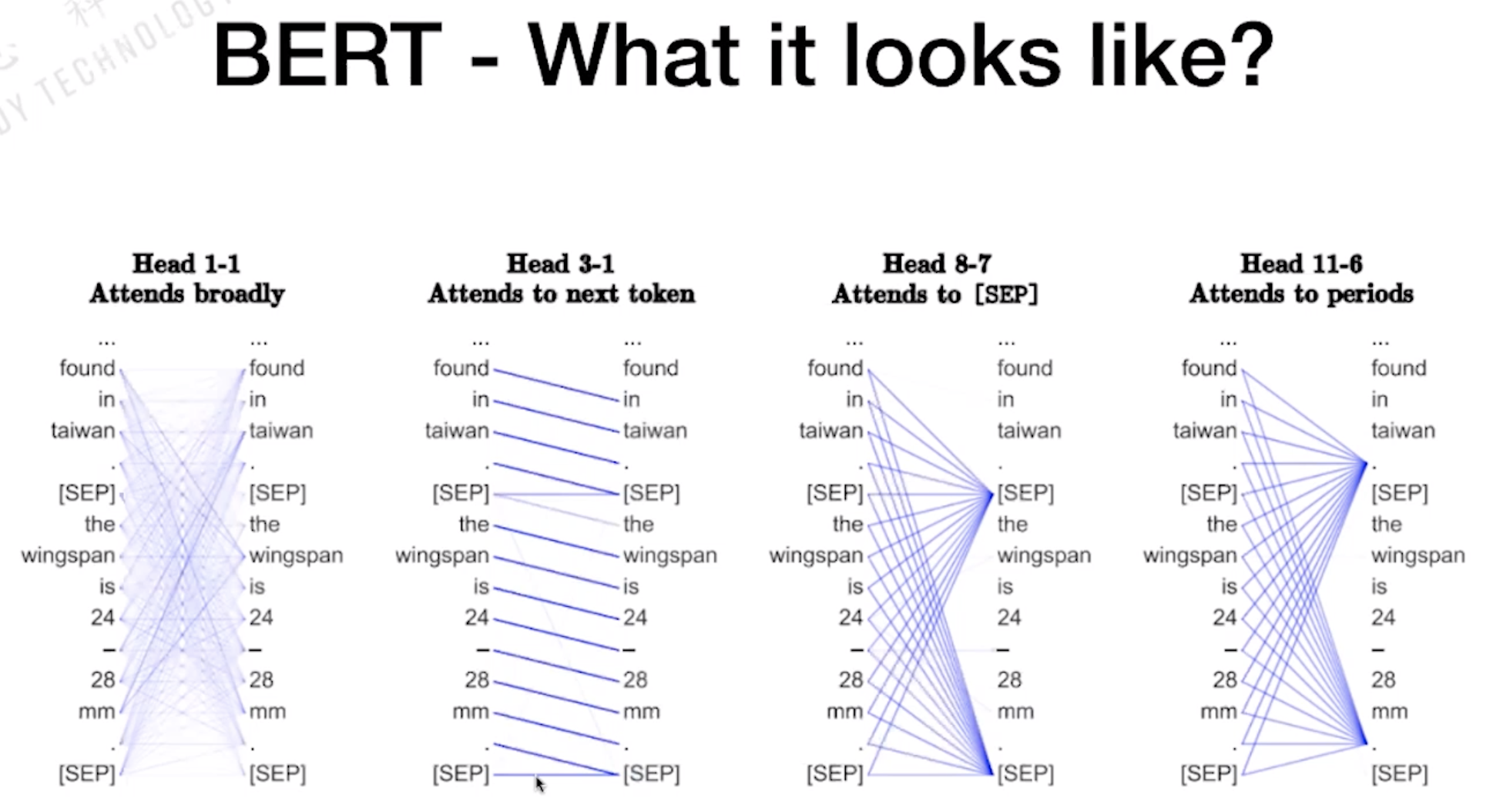

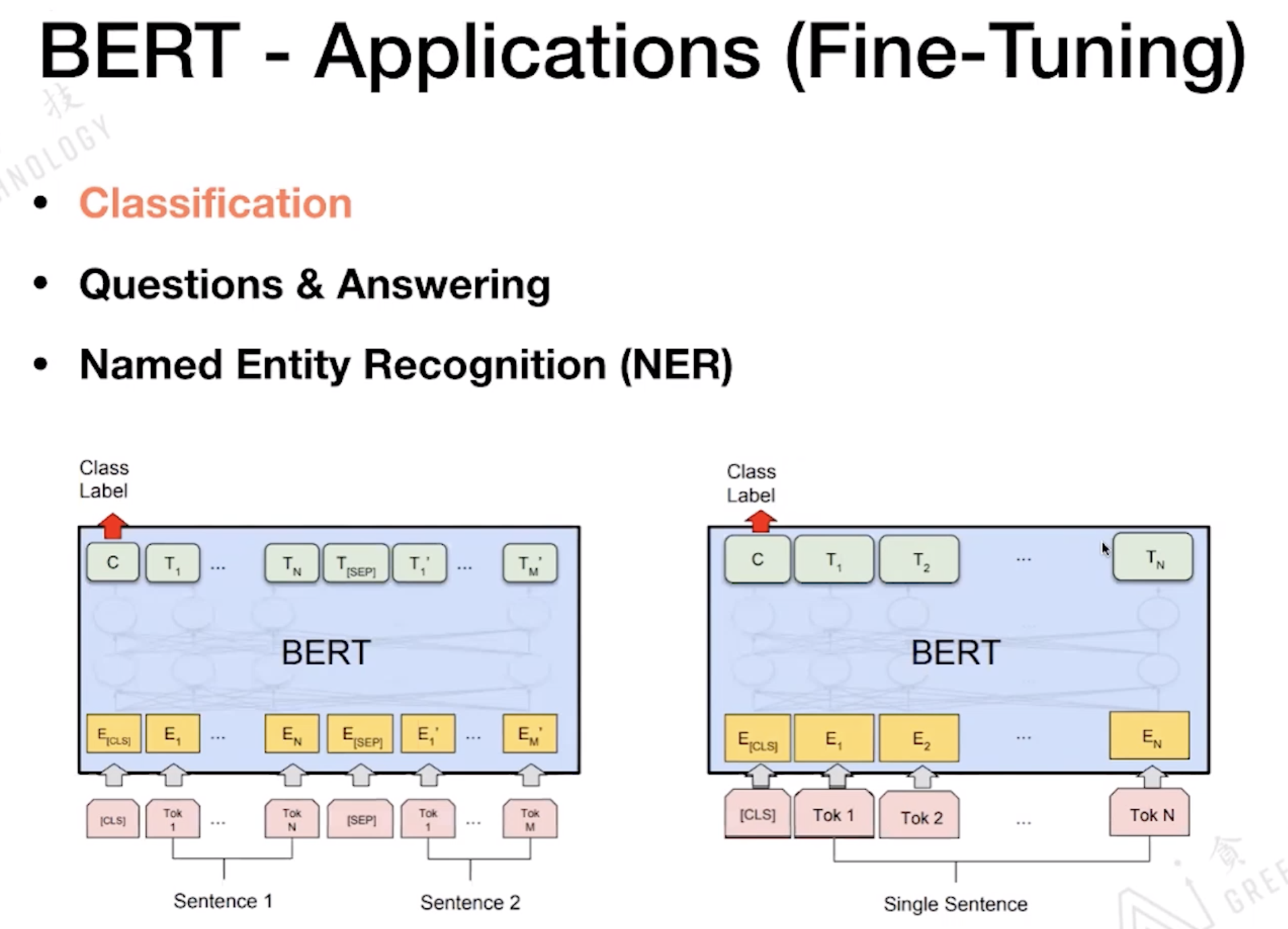
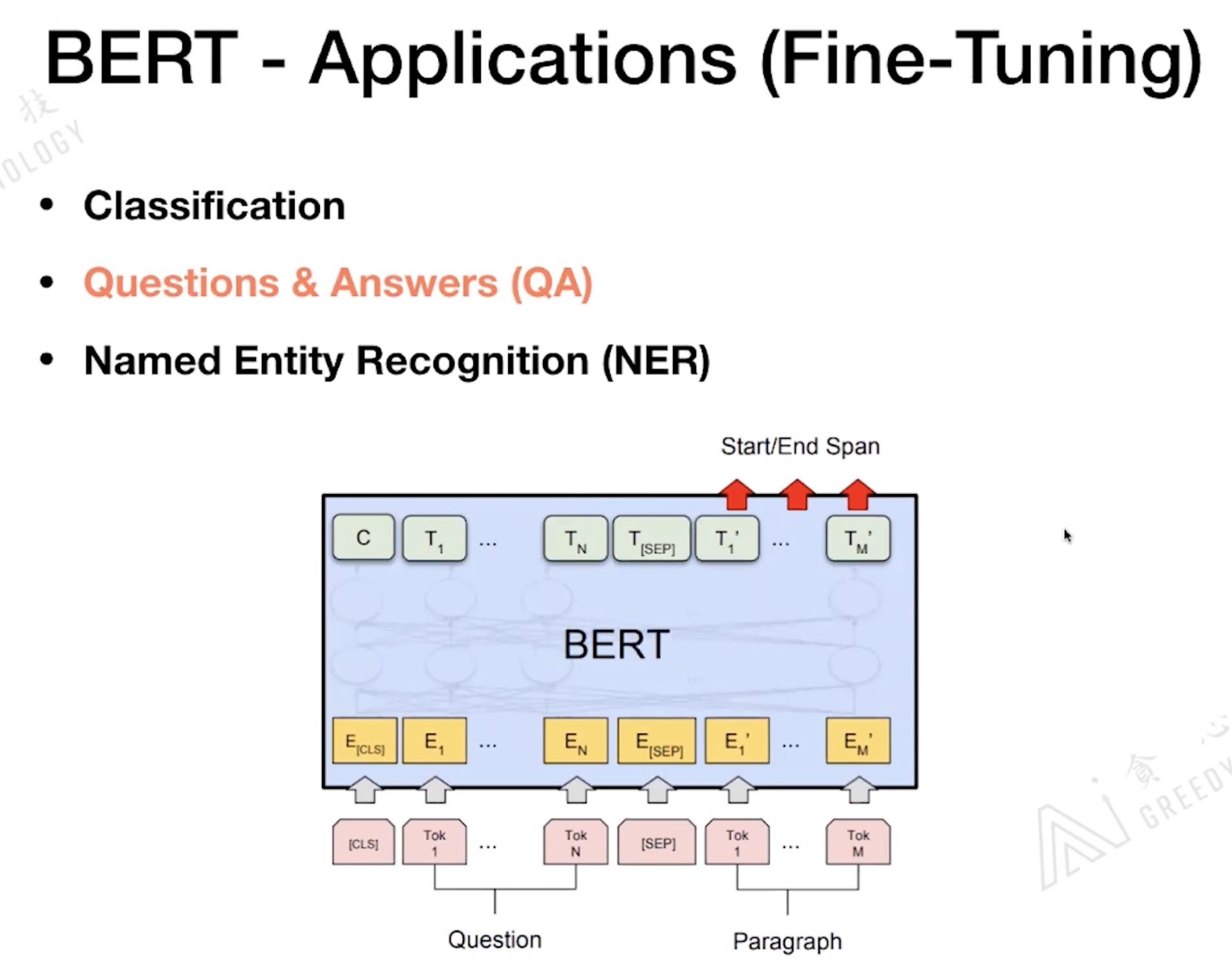
阅读理解是QA加难的版本
3. Recap

每个word都是这句话的所有信息组成的
Bert Training 40+ times, Fine-tune 2~4 times
every token: 12 * 768, 12 层的 Transformer.
Bert 主要的缺陷就是太大了.
Checking if Disqus is accessible...