spark 基础概念复习 3.2
1. 第1部分
任务的提交:
(1). run-example SparkPi 100
(2). spark-shell
(3). spark-submit
--master:
1 | local local[2] local[*] |
HDFS 处理 myha01 这个 nameservice 的方式非常的暴力:
所有的请求,其实都会给每个 namenode 都发送, 但是只有 active 的 namenode才会进行处理,进行回复
if (namenode.getServiceStage() == “standby”) {} else : …
2. 第2部分
核心功能: SparkContext, 存储体系, 执行引擎 DAGScheduler, 部署模式
扩展功能: SQL, Streaming, GraphX, MLlib, SparkR, Pyspark
核心概念:
Application
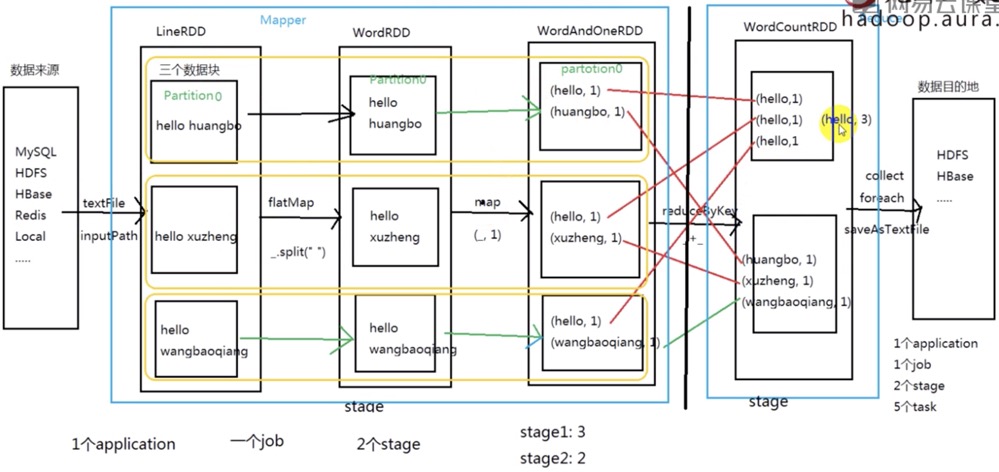
Job 切分标准: 从前往后找action的算子
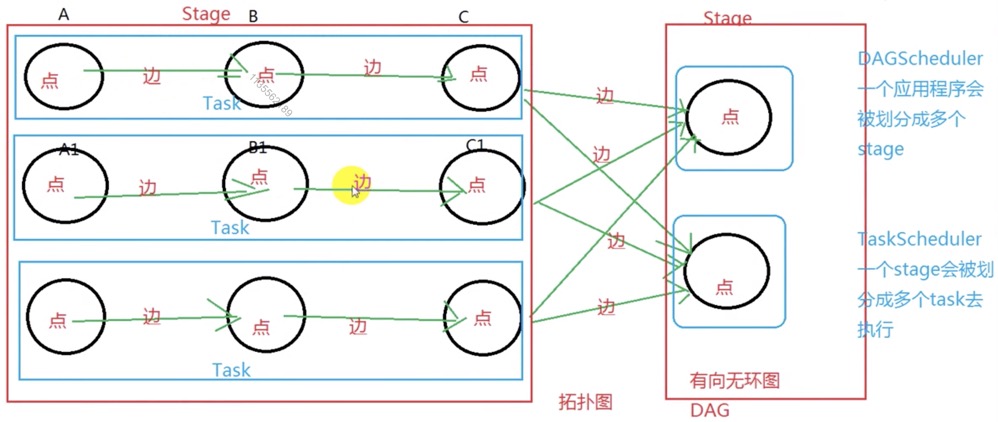
Stage 切分标准: 从后往前找宽依赖的算子
Task在spark中,Task的类型分为2种:ShuffleMapTask 和 ResultTask;简单来说,DAG的最后一个阶段会为每个结果的 partition 生成一个 ResultTask, 即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!
而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中。
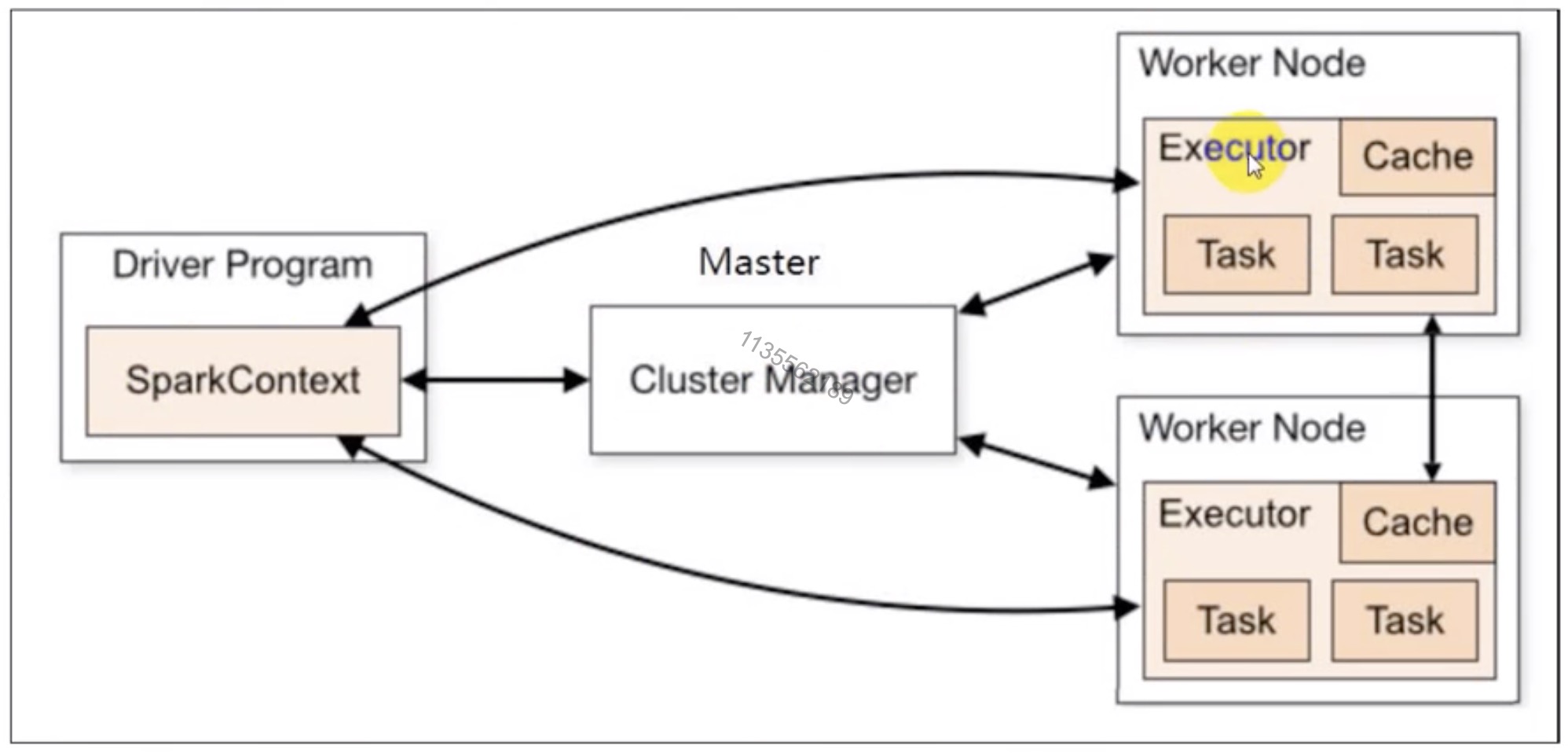
Driver Application: 客户端驱动程序, 也可以理解为客户端应用程序,用于将任何程序转换为 RDD 和 DAG, 并与 Cluster Manager 进行通信与调度.
ClusterManager
Driver
Executor
Master, Worker, Client
deploy-mode 主要针对 yarn: client cluster
基本架构:
编程模型:
1). 获取编程入口
--->SparkContext2). 通过编程入口使用不同的方式加载数据得到一个
数据抽象--->RDD3). 针对加载得到的数据抽象调用不同的
算子进行处理--->Transformation + Action4). 针对结果数据进行处理 RDD/Scala 对象 或 集合
--->print / save 存储5). 关闭编程入口
--->sparkContext.stop()sparkSQL
sparkStreaming
&
sparkCore 一模一样
唯一不相同的地方就是: 编程入口, 数据抽象, 算子
RDD 摘要1:
(1) 概念: 弹性分布式数据集, 不可变的, 可分区的分布式集合
(2) 属性:
- A list of partitions
- A function for computing on other RDDs
- A list of dependencies on other RDDs
- Optionally, a Partition for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
RDD 摘要2:
(1). 概念
弹性分布式数据集
不可变的,可分区的分布式集合
(2). 五大属性
分区 (A list of partitions)
作用在每个分区之上的一个函数
依赖: 宽依赖 & 窄依赖
KeyValueRDD 分区器
RDD 优先位置列表
(3). 官方, 创建 RDD 的2种方式
1 | parallelize() makeRDD() |
1 | textFile() 引用一个外部存储系统 |
作用在每个RDD之上的算子:
- Transformation. RDD —> RDD
- Action. RDD —> Scala 对象 or 集合
WordCount 各种流程的划分:
WordCount DAG 有向无环图:
Checking if Disqus is accessible...