SparkSql - 结构化数据处理 (下)
1. spark 整合 yarn
rdd.aggregateByKey(init_value: U) ((C, U) => (C,C) => C)
1.1 配置 Spark 整合 YARN
- 把 yarn-site.xml 复制到 $SPARK_HOME/conf 目录中
- 在使用 spark-submit 提交任务时候请这么执行资源调度系统:
spark-submit --master yarn --deploy-mode client
但是有可能出现异常
1.2 Spark-Shell 测试
1 | 只能这么启动 |
原来:
1 | spark-shell |
1.3 Spark-Submit 测试
1 | 只能这么启动 |
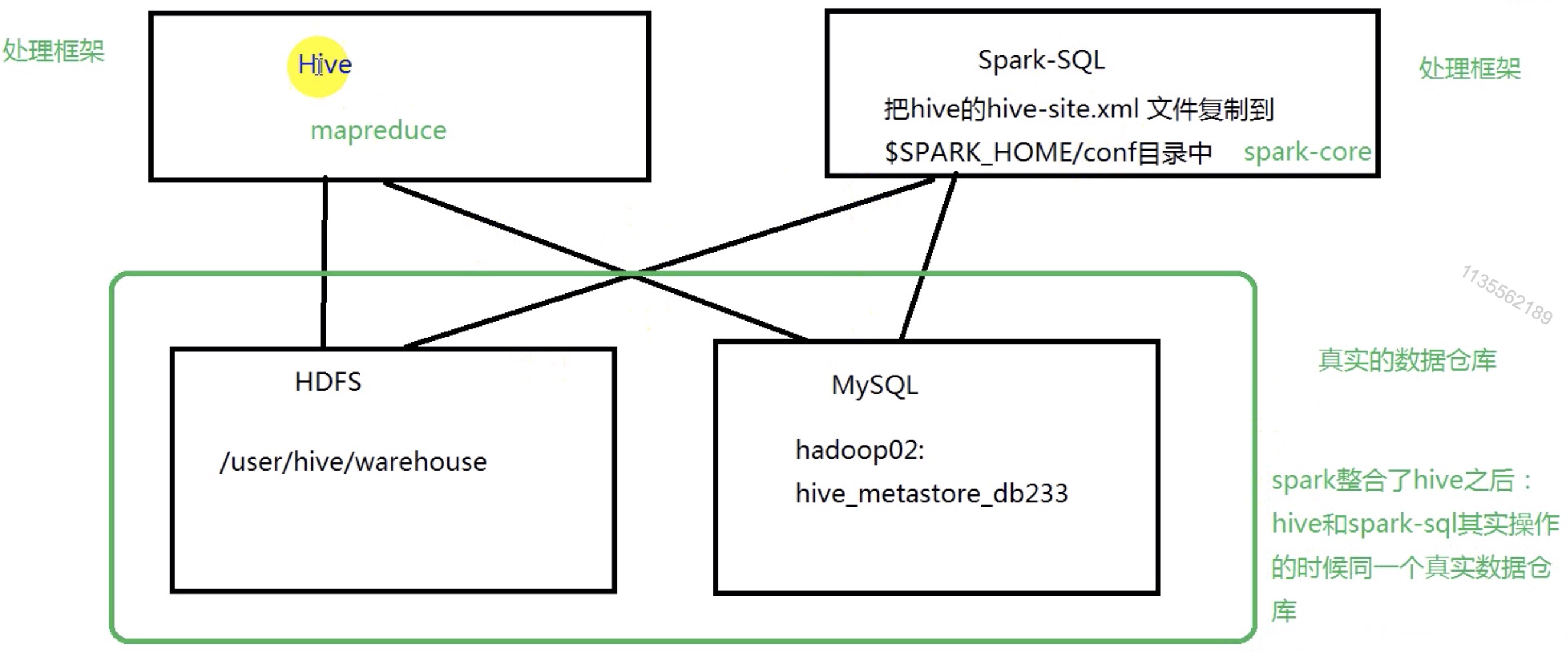
2. spark 整合 hive
2.1 Spark 自带元数据库 &
如果用户直接运行bin/spark-sql命令。会导致我们的元数据有两种状态:
1、in-memory状态:
如果SPARK-HOME/conf目录下没有放置hive-site.xml文件,元数据的状态就是in-memory, 也就是使用自带的 derby 在当前会话中有效
1 | create table student(id int, name string, sex string, age int, department string) |
spark-sql 在 hadoop02 和 hadoop03 中启动的时候,都各自初始化了一个元数据库
所以在 hadoop02 上创建的元数据库,在 hadoop03 上启动的 spark-sql 不能共用数据.
spark-sql 的使用有2种模式
2.2 Spark 整合hive配置
2、hive状态:
如果我们在SPARK-HOME/conf目录下放置了,hive-site.xml文件,那么默认情况下
spark-sql的元数据的状态就是hive.
Reference
- Spark实例-自定义聚合函数
- Spark UDF使用详解及代码示例
- 看了之后不再迷糊-Spark多种运行模式,俺是亮哥
- Spark SQL, DataFrame 和 Dataset 编程指南
- Spark2.x学习笔记:14、Spark SQL程序设计
- SparkSQL学习 1 2 3
- SparkSQL在有赞大数据的实践(二)
- How to convert rdd object to dataframe in spark
- 云课堂 SparkSQL 的数据源操作
- 大数据资料笔记整理
- HDOJ_1711_KMP 求匹配位置
Checking if Disqus is accessible...