Spark Tutorials 1 - Introduce、Ecosysm、Features、Shell Commands
1. Spark - Introduction
- Objective – Spark Tutorial
- Introduction to Spark Programming
- Spark Tutorial – History
- Why Spark?
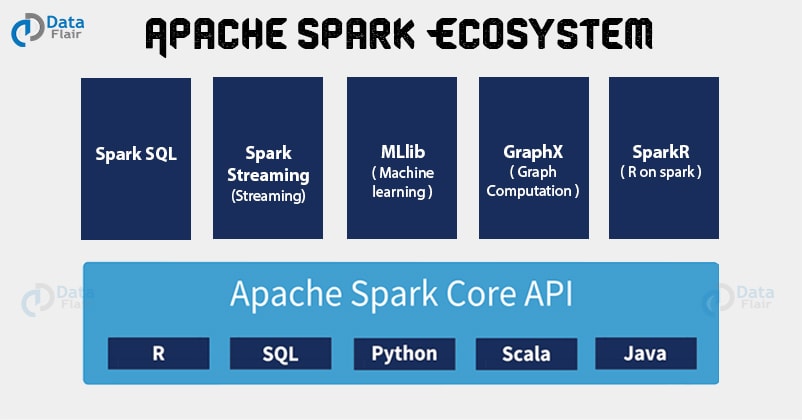
- Apache Spark Components
a. Spark Core
b. Spark SQL
c. Spark Streaming
Spark Tutorial – Learn Spark Programming
2. Spark - Ecosystem
3. Spark - Features
4. Spark - Shell Commands
4.1 Create a new RDD
a) Read File from local filesystem and create an RDD.
1
2
3
4
| from pyspark import SparkConf , SparkContext
lines = sc.textFile("/Users/blair/ghome/github/spark3.0/pyspark/spark-src/word_count.text", 2)
lines.take(3)
|
b) Create an RDD through Parallelized Collection
1
2
3
4
5
| from pyspark import SparkConf , SparkContext
no = [1, 2, 3, 4, 5, 6, 8, 7]
noData = sc.parallelize(no)
|
c) From Existing RDDs
1
2
3
| words= lines.map(lambda x : x + "haha")
words.take(3)
|
4.2 RDD Number of Items
4.3 Filter Operation
1
| scala> val DFData = data.filter(line => line.contains("DataFlair"))
|
1
| scala> data.filter(line => line.contains("DataFlair")).count()
|
4.5 Read RDD first 5 item
1
2
| scala> data.first()
scala> data.take(5)
|
Let’s run some actions
1
2
3
| noData.count()
noData.collect()
|
4.6 Spark WordCount
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| from pyspark import SparkConf , SparkContext
from operator import add
sc.version
lines = sc.textFile("/Users/blair/ghome/github/spark3.0/pyspark/spark-src/word_count.text", 2)
lines = lines.filter(lambda x: 'New York' in x)
words = lines.flatMap(lambda x: x.split(' '))
wco = words.map(lambda x: (x, 1))
word_count = wco.reduceByKey(add)
word_count.collect()
|
4.7 Write to HDFS
1
| word_count.saveAsTextFile("hdfs://localhost:9000/out")
|
Reference


Checking if Disqus is accessible...