Spark SQL几种Join实现
有两种方式使用SparkSQL
- 是直接写sql语句,这个需要有元数据库支持,例如Hive等
- 通过Dataset/DataFrame编写Spark应用程序。
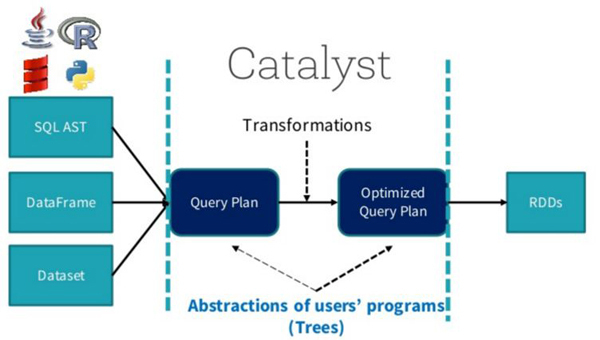
1. SparkSQL总体流程
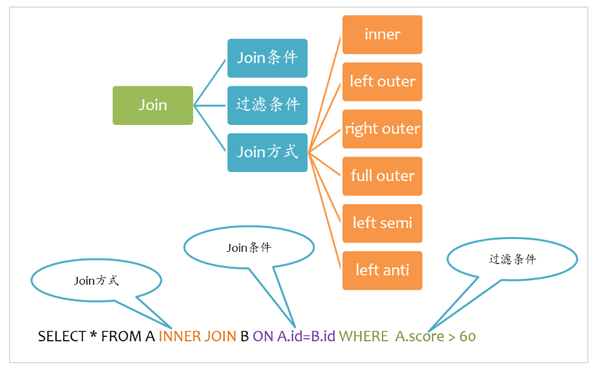
2. Join基本要素
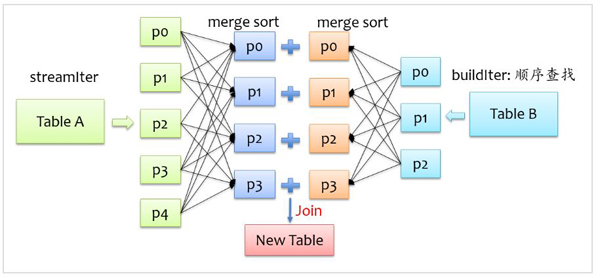
Join基本实现流程
Spark将参与Join的两张表抽象为流式遍历表(streamIter)和查找表(buildIter),通常streamIter为大表,buildIter为小表,我们不用担心哪个表为streamIter,哪个表为buildIter,这个spark会根据join语句自动帮我们完成.
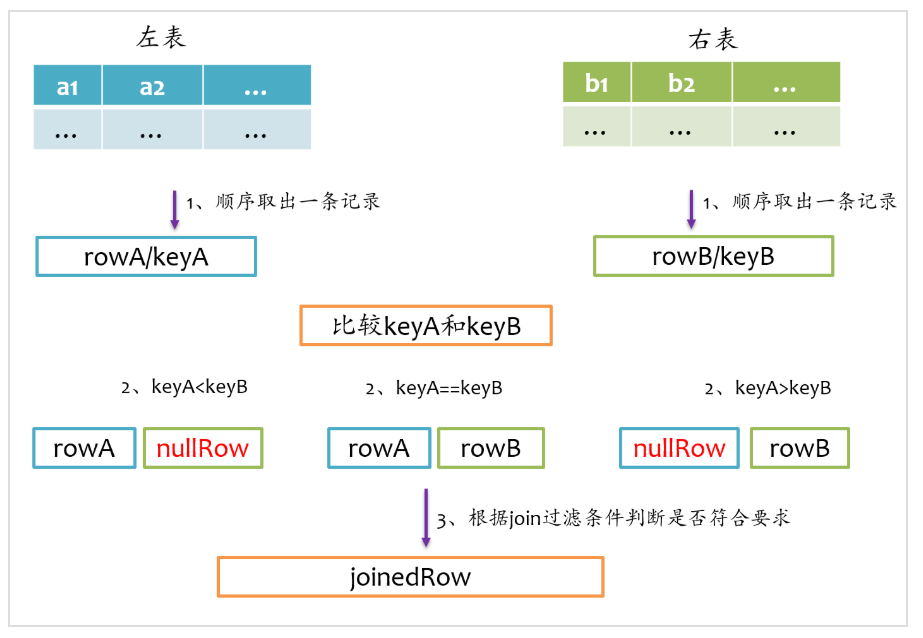
2.1 sort merge join实现
要让两条记录能join到一起,首先需要将具有相同key的记录在同一个分区,所以通常来说,需要做一次shuffle,map阶段根据join条件确定每条记录的key,基于该key做shuffle write,将可能join到一起的记录分到同一个分区中,这样在shuffle read阶段就可以将两个表中具有相同key的记录拉到同一个分区处理.
2.2 broadcast join实现
当buildIter的估计大小不超过参数spark.sql.autoBroadcastJoinThreshold设定的值(默认10M),那么就会自动采用broadcast join,否则采用sort merge join.
2.3 hash join实现
2.4 inner join
2.5 left outer join
2.6 right outer join
2.7 full outer join
full outer join仅采用sort merge join实现,左边和右表既要作为streamIter,又要作为buildIter,其基本实现流程如下图所示:
2.8 left semi join
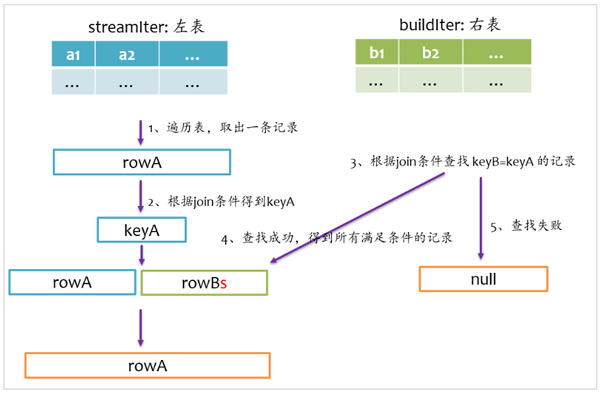
2.9 left anti join
3. Spark 执行图
Join是数据库查询中一个非常重要的语法特性,在数据库领域可以说是“得join者得天下”,SparkSQL作为一种分布式数据仓库系统,给我们提供了全面的join支持,并在内部实现上无声无息地做了很多优化,了解join的实现将有助于我们更深刻的了解我们的应用程序的运行轨迹.
Checking if Disqus is accessible...