Used for storing intermediate results during task execution, such as Shuffle and Join.
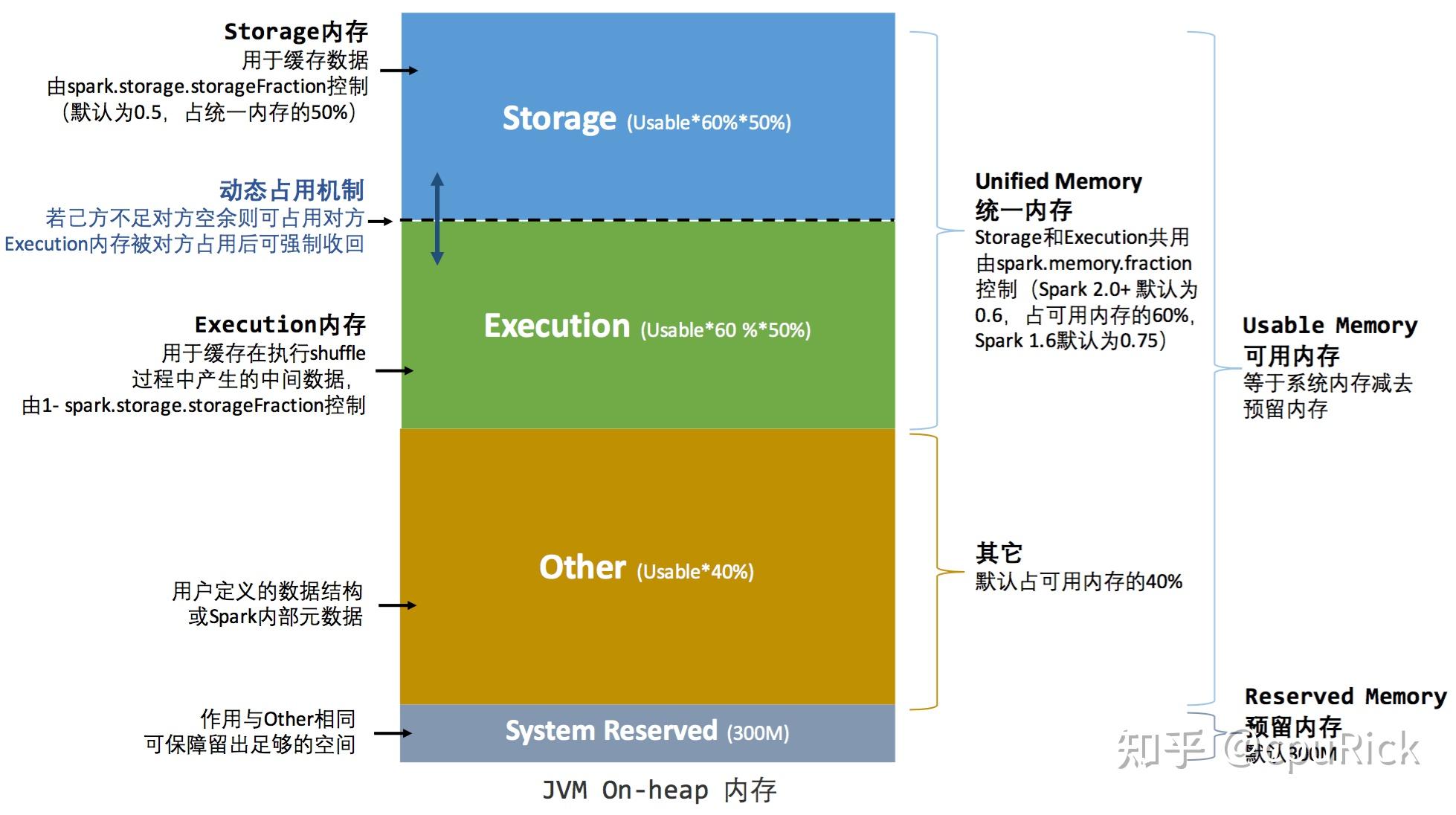
Storage Memory
Used for caching data (e.g., RDD.cache() or Dataset.persist()) and broadcasting variables.
Dynamic Allocation
Execution and Storage Memory share the same region. Unused memory can be reallocated between them.
Key Parameters
- spark.memory.fraction: Fraction of JVM heap allocated to Execution and Storage (default 0.6). - spark.memory.storageFraction: Fraction allocated to Storage (default 0.5, i.e., 30% of JVM heap).
2. Optimize Spark memory
Optimization Method
Description
Adjust Parallelism
Increase parallelism to reduce the size of each partition. Configure with spark.default.parallelism or RDD.repartition().
Optimize Memory Config
Increase spark.executor.memory and spark.driver.memory. Enable off-heap memory with spark.memory.offHeap.enabled=true and configure spark.memory.offHeap.size.
Serialization Optimization
Use Kryo serializer: spark.serializer=org.apache.spark.serializer.KryoSerializer. Register custom classes for better performance.
Efficient Caching
Cache only necessary data and release it in time using RDD.unpersist().
Shuffle Optimization
Enable shuffle compression (spark.shuffle.compress=true) and avoid wide dependencies (e.g., use ReduceByKey instead of GroupByKey).
3. Troubleshoot OutOfMemory
Steps to Troubleshoot
Description
Check Logs
Identify if the issue is due to Executor or Driver memory. Look for errors like GC overhead limit exceeded or Java heap space.
Analyze Partition Count
Check if there are too few partitions, leading to large data per partition.
Inspect Wide Dependencies and Cache
Investigate whether wide dependencies (e.g., GroupByKey) or excessive caching caused the issue.
Resolution Methods
Description
Adjust Memory Settings
Increase spark.executor.memory and spark.driver.memory. Enable off-heap memory (spark.memory.offHeap.enabled=true).
Increase Partition Count
Use RDD.repartition() or RDD.coalesce() to increase partitions and reduce data size per partition.
Optimize DAG
Avoid wide dependencies (e.g., GroupByKey), use narrow dependencies (e.g., ReduceByKey).
Release Cache
Use RDD.unpersist() to release unnecessary cached data.
4. Off-Heap Memory (堆外内存)
Aspect
Description
Definition
Off-heap memory refers to memory outside the JVM heap, typically used for serialized data storage to reduce GC pressure.
Enable Off-Heap Memory
Configure spark.memory.offHeap.enabled=true and set spark.memory.offHeap.size (e.g., 4g).
Use Cases
Useful for large datasets with high GC overhead or for storing serialized data streams.
Checking if Disqus is accessible...